Java 概述 命令行执行Java代码 1 2 3 4 javac 文件名.java java 主类名
转义字符 通过 / 对后面的字符进行转义,以达到不同的目的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class ChangeChar { public static void main (String[] args) { System.out.println("北京\t天津\t上海" ); System.out.println("北京\n天津\n上海" ); System.out.println("C:\\code\\java" ); System.out.println("老师说:\"认真学习\"" ); System.out.println("老师说:\'认真学习\'" ); System.out.println("你好,世界\r哈喽" ); } }
输出结果:
注释 注释不会被Java虚拟机JVM编译,故而可以在代码上添加注释,方便他人和自己阅读
单行注释:// 注释内容
多行注释:/* 注释内容 */
文档注释:注释内容可以被JDK提供的工具 javadoc 所解析,生成一套以网页文件形式体现的该程序的说明文档,一般写在类的上面
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public class ChangeChar { public static void main (String[] args) { System.out.println("北京\t天津\t上海" ); System.out.println("北京\n天津\n上海" ); System.out.println("C:\\code\\java" ); System.out.println("老师说:\"认真学习\"" ); System.out.println("老师说:\'认真学习\'" ); System.out.println("你好,世界\r哈喽" ); } }
生成说明文档的命令语句
1 javadoc -d d:\\文件地址 -author -version 主类文件名.java
变量 变量的定义 变量是内存中一个存储空间的表示,可以通过操作该变量来对该内存进行操作
变量的声明
变量的赋值
变量的声明和赋值的组合
注意:
变量必须先声明,后使用
变量可以在同一类型下不断变化,即可频繁赋值
变量在同一作用域下,不能同名
+号的使用
当左右两边都是数值类型时,则做加法运算
当左右两边有一方为字符串类型,则做拼接运算
数据类型 数据类型的分类
整数类型 Java的整数类型用于存储整数值数据,比如2,3,230等等
细节:
整型所占的字节空间不会随操作系统的变化而变化,以保证Java程序的可移植性
Java的整型常量默认为int类型,声明long型常量需要在其后加 ‘l’ 或 ‘L’
Java程序中变量常声明为int类型,除非不足以表示大数,才使用long
bit:计算机中最小的存储单位
byte:计算机中基本存储单元,1byte = 8bit
浮点类型 Java的浮点类型可以表示一个小数,比如 123.4,7.8,0.12等等
浮点数在机器中存放形式为符号位 + 指数位 + 尾数位
尾数部分可能会丢失,造成精度损失(小数都是近似值)
细节:
浮点型所占的字节空间不会随操作系统的变化而变化,以保证Java程序的可移植性
Java的浮点型常量默认为double类型,声明float型常量需要在其后加 ‘f’ 或 ‘F’
浮点型常量有两种表示方式:十进制表示法和科学计数法(例如:5.12e2表示5.12 * 10的2次方,5.12E-2表示5.12 / 10的2次方)
通常情况下,应该使用double类型,因为它比float类型更精确
如果使用计算出的浮点数进行比较(例如2.7和8.1/3比较),需采用两数相减的绝对值不超过某个范围来判断两者是否相等,因为计算机计算的原因8.1/3不等于2.7,而等于一个近似2.7的小数
字符类型 字符类型可以表示单个字符,字符类型是char,char是两个字节(可以存放汉字),多个字符可以采用String类进行存储。字符类型可以存储一个数字,当输出该字符类型的变量时,不会打印数字,而是打印该数字在Unicode编码表中对应的字符
细节:
字符常量是用单引号括起来的单个字符,例如:char c1 = ‘a’
用双引号括起来的是String类,不能用于字符类型
Java中允许使用转义字符 ‘' 来将其后的字符转变为特殊字符型常量。例如:char c2 = ‘\n’; 其中 ‘\n’ 表示换行符
在Java中,char的本质是一个整数,在输出时,是unicode编码表对应的字符
可以直接给char类型的变量赋值一个整数,然后输出时,会按照unicode编码表输出对应的字符
char类型可以进行运算,相当于一个整数,因为它都对应有unicode码
1 2 3 4 5 6 7 8 9 10 11 12 public class CharTest { public static void main (String[] args) { char c1 = 'a' ; System.out.println(c1); System.out.println((int )c1); char c2 = 97 ; System.out.println(c2); char c3 = 'b' + 1 ; System.out.println((int )c3); System.out.println(c3); } }
布尔类型 true表示真,false表示假,一般用于选择分支
细节:不可以用0或非0的整数赋值给布尔类型的变量
编码 字符集标准定义了字符与数字码之间的映射关系,编码方案则是规定如何存储该数字码,采用多少个字节来存储该数字码
字符集标准:
Unicode:定义了世界上大部分字符对应的数字码
编码方案
UTF-8:大小可变的方案,字母的数字码使用1个字节存储,汉字的数字码使用3个字节存储
UTF-16:固定不变的方案,字母和汉字的数字码都是采用2个字节存储,很浪费空间,但是内存中存储字符都是采用该编码方案存储
UTF-32:固定不变的方案,字母和汉字的数字码都是采用4个字节存储
即使编码方案,又是字符集标准
ASCII:定义了128个字符对应的数字码,数字码采用1个字节存储
GBK:可以表示汉字,字母的数字码使用1个字节存储,汉字的数字码采用2个字节存储
GB2312:可以表示汉字,但是存储的汉字数量少于GBK
BIG5:可以表示繁体汉字,台湾、澳门、香港常用
数据类型转换 自动类型转换 当Java程序在进行赋值或者运算时,精度小的类型自动转换为精度大的数据类型,这就是自动类型转换
以下为低精度类型到高精度类型的排序:
细节:
自动提升原则:表达式结果的类型自动提升为 操作书中最大的类型
boolean类型不参与转换
byte, short 不会和 char 进行相互自动转换
byte,short,char 它们三者之间可以进行计算,在计算时首先转换为int类型(例如:short s1 = 1; short s2 = 2; 则 s1 + s2 的结果是int类型
将精度大的数据类型变量直接赋值给精度小的数据类型变量,会直接报错
short s1 = 19; 或者 byte b1 = 1; 可以赋值的原因是整数赋值会先判断该常量是否超过该类型的范围,再判断类型。而小数赋值或者变量赋值则是直接判断类型
强制类型转换 自动类型转换的逆过程,将容量大的数据类型转换为容量小的数据类型。使用时要加上强制类型转换符(),但可能造成精度降低或溢出,格外要注意。
1 2 3 4 5 6 7 public class ChangeChar { public static void main (String[] args) { double d1 = 1.1 ; int i1 = (int )d1; System.out.println(i1); } }
细节:
强转符号只针对于最近的操作数有效,往往会使用小括号提升优先级
char类型可以保存int的常量值,但不能保存int的变量值,需要强转
基本数据类型和String类型的转换
基本类型转String类型:将基本类型的值 + “” 即可得到
String类型转基本数据类型:通过基本类型的包装类调用parseXX方法即可得到
1 2 3 4 5 6 7 8 9 10 11 12 13 public class ChangeChar { public static void main (String[] args) { boolean b1 = true ; String s1 = b1 + "" ; System.out.println(s1); String s2 = "123" ; System.out.println(Integer.parseInt(s2)); System.out.println(s2.charAt(0 )); } }
注意:在将String类型转成基本数据类型时,要确保String类型能够转成有效的数据,比如可以把”123”转成整数,但是不能把”hello”转成一个整数
运算符 算术运算符
注意:a % b 的本质是 a - a / b * b 计算后的结果,所以 10 % - 3 的结果为 1,而非 - 1
关系运算符
关系运算符的结果都是boolean类型,结果要么是true,要么是false
关系表达式经常用在if结构的条件中或循环结构的条件中
运算符 含义
>
大于
>=
大于或者等于
<
小于
<=
小于或者等于
==
等于
!=
不等于
逻辑运算符 用于连接多个条件(多个关系表达式),最终结果是一个boolean值
a&b:&叫逻辑与,规则:当a和b同时为true,则结果为true,否则为false
a&&b:&&叫短路与,规则:当a和b同时为true,则结果为true,否则为false
a|b:|叫逻辑或,规则:当a和b,有一个为true,则结果为true,否则为false
a||b:||叫短路或,规则:当a和b,有一个为true,则结果为true,否则为false
!a:叫取反,或者非运算。当a为true,则结果为false,当a为false是,结果为true
a^b:叫逻辑异或,当a和b不同时,则结果为true,否则为false
细节:
逻辑与 & 和短路与 && 的区别:当短路与的一个条件为假时,不会判断第二个条件,直接得到结果为假,而逻辑与无论第一个条件是什么,都会判断第二个条件。故而开发中常用短路与,效率高
逻辑或 | 和 短路或 || 的区别:短路或的一个条件为真时,不会判断第二个条件,直接得到结果为真,而逻辑或无论第一个条件是什么,都会判断第二个条件。故而开发中常用短路或,效率高
赋值运算符
基本赋值运算符:=
复合赋值运算符:+=、-=、*=、/=,%=
细节:
运算顺序从右向左
赋值运算符的左边只能是变量,右边可以是常量、表达式、变量
复合运算符会进行类型转换。例如:byte b = 2; b += 2; 等价于 b = (byte)b + 2; 语句b = b + 2; 是错误的
三元运算符 基本语法:条件表达式 ? 表达式1 : 表达式2
如果条件表达式为true,运算后的结果是表达式1
如果条件表达式为false,运算后的结果是表达式2
细节:表达式1和表达式2要为可以赋给接收变量的类型(或是可以自动转换)
运算符优先级 优先级从上到下依次降低
细节:只有单目运算符(++、–、~、!)和赋值运算符是从右向左运算的
标识符 概念:Java 对各种变量、方法和类邓命名时使用的字符序列称为标识符
命名规则(必须遵守):
由26个英文字母大小写,0-9,_或$组成
数字不可以开头
不可以使用关键字和保留字,但能包含关键字和保留字
Java中严格区分大小写,长度无限制
标识符不能包含空格。例如 int a b = 90;
命名规范(不是必须):
包名:多单词组成时所有字母都小写。例如:com.itheima
类名、接口名:多单词组成时,所有单词的首字母大写。例如:userClass
变量名、方法名:多单词组成时,第一个单词首字母小写,第二个单词开始每个单词首字母大写。例如:tagName
常量名:所有字母都大写。多单词时每个单词之间用下划线连接。例如:TAX_RATE
键盘输入语句 Java中通过Scanner类扫描用户通过键盘输入的数据,具体使用步骤:
导入类
创建该对象的实例
通过该对象的方法扫描得到具体数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import java.util.Scanner;public class ScannerClass { public static void main (String[] args) { Scanner myScanner = new Scanner (System.in); System.out.println("请输入姓名:" ); String name = myScanner.next(); System.out.println("请输入年龄:" ); int age = myScanner.nextInt(); System.out.println("请输入薪水:" ); double salary = myScanner.nextDouble(); System.out.println("此人的信息如下:" ); System.out.println("姓名=" + name + " 年龄=" + age + " 薪水=" + salary); } }
位运算符 四种进制 二进制:以0b开头。例如:int n1 = 0b1010;
八进制:以0开头。例如:int n2 = 01010;
十进制:常用进制。例如:int n3 = 1010;
十六进制:以0x开头。例如:int n4 = 0x1010;
二进制转换成十进制 规则:从最低位开始,将每个位上的数提取出来,乘以2的(位数-1)次方,然后就和。
例如:0b1011(二进制)= 1 * 2 ^3 + 0 * 2 ^ 2 + 1 * 2 ^ 1 + 1 * 2 ^ 0 = 8 + 0 + 2 + 1 = 11(十进制)
八进制转换成十进制 规则:从最低位开始,将每个位上的数提取出来,乘以8的(位数-1)次方,然后就和。
例如:0234(八进制)= 2 * 8 ^ 2 + 3 * 8 ^ 1 + 4 * 8 ^ 0 = 156(十进制)
十六进制转换成十进制 规则:从最低位开始,将每个位上的数提取出来,乘以16的(位数-1)次方,然后就和。
例如:0x23A(十六进制)= 10 * 16 ^ 0 + 3 * 16 ^ 1 + 2 * 16 ^ 2 = 570(十进制)
十进制转换成二进制 规则:将该数不断除以2,直到商为0为止,然后将每步得到的余数倒过来,就是其对应的二进制
例如:34(十进制)= 0b100010(二进制)
十进制转换为八进制 规则:将该数不断除以8,直到商为0为止,然后将每步得到的余数倒过来,就是其对应的二进制
例如:131(十进制)= 0203(八进制)
十进制转换成十六进制 规则:将该数不断除以16,直到商为0为止,然后将每步得到的余数倒过来,就是其对应的二进制
例如:237(十进制)= 0xED(十六进制)
二进制转换成八进制 规则:从低位开始,将二进制数每三位一组,转成对应的八进制数即可
例如:0b11010 = 0325
二进制转换成十六进制 规则:从低位开始,将二进制数每四位一组,转成对应的十六进制数即可
例如:0b11010101 = 0xD5
八进制转换成二进制 规则:将八进制数的每一位,转成对应的一个三位的二进制数即可
例如:0237 = 0b010011111
十六进制转换成二进制 规则:将十六进制每一位,转成对应的一个四位的二进制数即可
例如:0x23B = 0b001000111011
原码、反码、补码
二进制数的最高位是符号位:0表示正数,1表示负数
正数的原码、反码、补码都是一样的(三码合一)、
负数的反码=它的原码符号位不变,其他位取反
负数的补码=它的反码+1,负数的反码=负数的补码-1
0(十进制)的反码和补码都是0
Java没有无符号位,换言之,Java中的数都是有符号的
在计算机运算的时候,都是以补码的方式来进行运算
运算结果都是看原码(重点)
按位与/或/异或/取反 按位与&:两位全为1,结果为1,否则位0
按位或|:两位有一个为1,结果为1,否则为0
按位异或^:两位一个为0,一个为1,结果为1,否则为0
按位取反~:每一位都采用0变1,1变0的规则进行运算
计算过程都是用的二进制补码
算术右移/左移、逻辑右移 算术右移>>:低位溢出,符号位不变,并用符号位补溢出的高位
1 >> 2:0000 0000 0000 0001 => 0000 0000 0000 0000。所以结果为0
本质是 1 / 2 / 2 = 0
算术左移<<:符号位不变,低位补0
1 << 2:0000 0000 0000 0001 => 0000 0000 0000 0100。所以结果为4
本质是 1 * 2 * 2 = 4
逻辑右移>>>:低位溢出,高位补0(和算术右移的区别就在于高位是用的0补的)
1 >>> 2:0000 0000 0000 0001 => 0000 0000 0000 0000。所以结果为0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class Test { public static void main (String[] args) { System.out.println(-1 << 2 ); System.out.println(" " ); System.out.println(-1 >> 2 ); System.out.println(" " ); System.out.println(-1 >>> 2 ); } }
控制结构 顺序 程序从上到下逐行地执行,中间没有任何判断和跳转
故而变量应在使用前声明
分支 单分支 1 2 3 if (条件表达式) { 执行代码块;(可以有多条语句) }
说明:当条件表达式为ture时,就会执行{}的代码。如果为false,就不执行.
特别说明,如果{}中只有一条语句,则可以不用{}。但是建议写上{}
双分支 1 2 3 4 5 if (条件表达式){ 执行代码块1 ; } else { 执行代码块2 ; }
说明:当条件表达式成立,即执行代码块1,否则执行代码块2。如果执行代码块只有一条语句,则{}可以省略,否则不可省略。
多分支 1 2 3 4 5 6 7 8 9 if (条件表达式1 ) { 执行代码块1 ; } else if (条件表达式2 ) { 执行代码块2 ; } ....... else { 执行代码块n; }
说明:
当条件表达式1成立时,执行代码块1
只有当条件表达式1不成立,才判断条件表达式2,如果成立,则执行代码块2
以此类推,如果所有表达式都不成立,则执行else的代码块
如果没有else,则所有表达式都不成立时,执行后面的代码
嵌套分支 基本介绍:在一个分支结构中又完整的嵌套了另一个完整的分支结构,里面的分支结构称为内层分支,外面的分支结构称为外层分支。建议:不要嵌套超过3层。
1 2 3 4 5 6 7 if (条件表达式1 ) { if (条件表达式2 ) { } else { } }
switch 分支 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 switch (表达式) { case 常量1 : 语句块1 ; break ; case 常量2 : 语句块2 ; break ; .... case 常量n: 语句块n; break ; default : default 语句块; break ; }
说明:
switch 关键字,表示switch分支
表达式对应一个值
case 常量1:当表达式的值为常量1,就执行语句块1
break:表达退出switch
如果和常量1匹配,就执行语句块1,如果没有匹配,就继续匹配常量2
如果一个都没有匹配上,执行default语句
细节:
表达式数据类型,应该和case后的常量类型保持一致,或者是可以自动转成可以相互比较的类型,比如输入的是字符,而常量是int
switch(表达式)中表达式的返回值必须是:(byte,short,int,char,enum(枚举),String)
case子句中的值必须是常量,而不能是变量
default子句是可选的,当没有匹配的case时,执行default
break语句用来在执行完一个case分支后使程序跳出switch语句块;如果没有写break,程序会顺序执行到switch结尾,除非遇到break
switch 和 if 推荐使用范围
如果判断的具体数值不多,而且符合byte、short、int、char,enum[枚举],
String这6种类型。虽然两个语句都可以使用,建议使用swtich语句。
其他情况:对区间判断,对结果为boolean类型判断,使用if,if的使用范围更广
循环 for 循环控制 1 2 3 for (循环变量初始化; 循环条件; 循环变量迭代) { 循环操作(可以是多条语句); }
for 关键字,表示循环控制
循环操作只有一条语句,可以省略{},建议不要省略
循环条件是返回一个布尔值的表达式
for(;循环判断条件;)中的初始化和变量迭代可以写到其它地方,但是两边的分
号不能省略。
循环初始值可以有多条初始化语句,但要求类型一样,并且中间用逗号隔开。循环变量迭代也可以有多条变量迭代语句,中间用逗号隔开
增强 for 循环控制 1 2 3 for (变量名 : 数组名或者集合名) { 循环操作(可以是多条语句); }
每次从数组或者集合中取出一个元素赋给冒号前的变量
可以通过操作变量来操作数组或者集合中的每一个元素
当数组或者集合元素取出完毕后,跳出循环
while 循环控制 1 2 3 4 while (循环条件) { 循环体(语句); 循环变量迭代; }
do while 循环控制 1 2 3 4 do { 循环体(语句); 循环变量迭代; } while (循环条件);
do while 是关键字
和 while 的区别是 它会先执行再判断
最后一定要有个分号
多重循环控制
将一个循环放在另一个循环体内,就形成了嵌套循环。其中,for,while,do….while均可以作为外层循环和内层循环(建议两层,最多不超过3层)
嵌套循环就是把内层循环当成外层循环的循环体。当只有内层循环的循环条件为false时,才会完全跳出内层循环,才可以结束外层的当次循环,开始下一次的循环。
设外层循环次数为m次,内层循环次数为n次,则内层循环体实际上需要执行m*n次。
break 概念:break语句用于终止某个语句块的执行,一般使用在switch或者循环中
细节:
break语句出现再多层嵌套的语句块中时,可以通过标签指明要终止的是哪一层语句块,一般不推荐使用
如果没有指定标签,默认退出最近的循环体
continue 作用:continue语句用于结束本次循环,继续执行下一次循环
continue语句出现在多层嵌套的循环语句体中时,可以通过标签指明要跳过的是哪一层循环,这个和前面的标签的使用规则一样
1 2 3 4 5 { ..... continue ; ..... }
return 作用:return使用在方法,表示跳出所在的方法。使用在main方法中,则会退出程序
数组 一维数组 概念:数组可以存放多个同一类型的数据。数组也是一种数据类型,是引用数据类型。
一维数组的使用
动态初始化
1 2 3 4 数据类型[] 数组名 = new 数据类型[大小]; 或者 数据类型 数组名[] = new 数据类型[大小]; 例如:int arr[] = new int [5 ];
以上代码是创建了一个数组名为arr的数组,它会在内存中开辟5个连续的int空间(4个字节),然后数组名arr则是指向该数组的第一个元素的首地址
1 2 3 4 5 6 数据类型[] 数组名; 或者 数据类型 数组名[]; 数组名 = new 数据类型[大小]
以上代码是先声明一个数组,此时该数组是null。创建后,然后数组名则是指向该数组的第一个元素的首地址
静态初始化
1 数据类型 数组名[] = {元素值, 元素值, .....}
当知道数组有多少元素以及每个元素的具体值,此时可以使用静态初始化
使用/访问/获取数组的元素:都是采用 数组[下标] 语法
数组的使用细节
数组是多个相同类型数据的组合,实现对这些数据的统一管理
数组中的元素可以是任何数据类型,包括基本类型和引用类型,但是不能混用。
数组创建后,如果没有赋值,有默认值
数据类型 默认值
int、short、byte、long
0
float、double
0.0
char
\u0000
boolean
false
String
null
使用数组的步骤:
数组的下标是从0开始的。
数组下标必须在指定范围内使用,否则报:下标越界异常,比如:int[] arr=new int[5]; 则有效下标为 0-4
数组属引用类型,数组型教据是对象(obiect)
数组的赋值机制 值拷贝 对于基本数据类型,进行变量赋值操作,会进行值拷贝。本质上是两个变量名在栈中都指向相同的值
1 2 3 4 5 6 7 8 public class Test { public static void main (String[] args) { int n1 = 10 ; int n2 = n1; System.out.println("n1 = " + n1); System.out.println("n2 = " + n2); } }
引用拷贝 对于引用数据类型,变量之间进行赋值操作,则是进行的引用拷贝。本质上是两个变量在栈中都指向相同的地址,该地址为堆中的地址
1 2 3 4 5 6 7 8 9 public class Test { public static void main (String[] args) { int [] arr1 = {1 , 2 , 3 }; int [] arr2 = arr1; arr2[0 ] = 2 ; System.out.println("arr2[0] = " + arr2[0 ]); System.out.println("arr1[0] = " + arr1[0 ]); } }
数组拷贝 如果要进行数组的拷贝,而不影响原始数组的数据,可以采用动态创建数组的方法,在堆空间中开辟一块新的空间,再将原始数组的数据赋值给新数组中
1 2 3 4 5 6 7 8 9 public class Test { public static void main (String[] args) { int [] arr1 = {1 , 2 , 3 }; int [] arr2 = new int [arr1.length]; for (int i = 0 ; i < arr2.length; i++) { arr2[i] = arr1[i]; } } }
反转数组的算法 方法1:通过交换法实现反转数组的数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class Test { public static void main (String[] args) { int [] arr = {11 , 22 , 33 , 44 , 55 , 66 }; int temp = 0 ; int len = arr.length; for (int i = 0 ; i < len / 2 ; i++) { temp = arr[i]; arr[i] = arr[len - 1 - i]; arr[len - 1 - i] = temp; } System.out.println("反转后的数组为" ); for (int i = 0 ; i < len; i++) { System.out.println(arr[i] + "\t" ); } } }
方法2:需要新创建一个数组,逆序遍历旧数组,顺序拷贝到新数组中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class Test { public static void main (String[] args) { int [] arr1 = {11 , 22 , 33 , 44 , 55 , 66 }; int [] arr2 = new int [arr1.length]; for (int i = arr1.length - 1 , j = 0 ; i > - 1 ; i--, j++) { arr2[j] = arr1[i]; } System.out.println("反转后的数组为" ); for (int i = 0 ; i < arr2.length; i++) { System.out.println(arr2[i] + "\t" ); } } }
数组扩容
方法1:新创建一个数组,新数组的容量要大于旧数组,并将旧数组的数据顺序拷贝到就数组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class Test { public static void main (String[] args) { int [] arr = {11 , 22 , 33 , 44 , 55 , 66 }; int [] arrNew = new int [arr.length + 1 ]; for (int i = 0 , j = 0 ; i < arr.length; i++, j++) { arrNew[j] = arr[i]; } arrNew[arrNew.length - 1 ] = 77 ; arr = arrNew; System.out.println("扩容后的数组为" ); for (int i = 0 ; i < arr.length; i++) { System.out.println(arr[i] + "\t" ); } } }
方法2:灵活控制是否输入
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import java.util.Scanner;public class Test { public static void main (String[] args) { int [] arr = {11 , 22 , 33 , 44 , 55 , 66 }; Scanner myScanner = new Scanner (System.in); do { System.out.println("请输入你要添加的数据:" ); int addNum = myScanner.nextInt(); int [] arrNew = new int [arr.length + 1 ]; for (int i = 0 , j = 0 ; i < arr.length; i++, j++) { arrNew[j] = arr[i]; } arrNew[arrNew.length - 1 ] = addNum; arr = arrNew; System.out.println("扩容后的数组为" ); for (int i = 0 ; i < arr.length; i++) { System.out.println(arr[i] + "\t" ); } System.out.println("是否要继续添加数据?y/n" ); char flag = myScanner.next().charAt(0 ); if (flag == 'n' ) { break ; } } while (true ); System.out.println("已退出添加......" ); } }
二维数组
声明二维数组的方式和一维数组的声明方式一致
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 数据类型[][] 数组名 = new [2 ][3 ]; 数据类型[][] 数组名; 数组名 = new int [2 ][3 ]; 数据类型[][] 数组名 = new [3 ][]; for (int i = 0 ; 数组名.length; i++) { 数组名[i] = new int [i + 1 ]; for (int j = 0 ; 数组名[i].length; j++) { 数组名[i][j] = i + 1 ; } } 数据类型[][] 数组名 = {{值1 , 值2 , 值3 }, {值4 , 值5 }, {值6 }};
二维数组的理解:一维数组的每一个元素都是一维数组,则该数组就是二维数组
获取二维数组元素:数组名[下标1][下标2]
1 2 3 4 5 6 7 8 9 10 11 12 public class Test { public static void main (String[] args) { int [][] arr = {{11 , 22 , 33 }, {44 , 55 , 66 }}; for (int i = 0 ; i < arr.length; i++) { for (int j = 0 ; j < arr[i].length; j++) { System.out.print(arr[i][j] + " " ); } System.out.println("" ); } } }
二维数组的内存布局
int[][] arr = new int[2][3]; arr[1][1] = 8;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public class YangHui { public static void main (String[] args) { int [][] yangHui = new int [10 ][]; for (int i = 0 ; i < yangHui.length; i++) { yangHui[i] = new int [i + 1 ]; for (int j = 0 ; j < yangHui[i].length; j++) { if (j == 0 || j == yangHui[i].length - 1 ) { yangHui[i][j] = 1 ; } else { yangHui[i][j] = yangHui[i - 1 ][j - 1 ] + yangHui[i - 1 ][j]; } } } for (int i = 0 ; i < yangHui.length; i++) { for (int j = 0 ; j < yangHui[i].length; j++) { System.out.print(yangHui[i][j] + " " ); } System.out.println(); } } }
细节:
二维数组的声明方式有:int[][] 数组名 或者 int[] 数组名[] 或者 int 数组名[][]
二维数组实际上是由多个一维数组组成,它的各个一维数组的长度可以相同,也可以不相同
面向对象编程 类与对象
类是抽象的概念,代表一类事物,例如:人类,猫类,即它是数据类型
对象是具体的,实际的,代表一个具体事物,即是实例
类是对象的模板,对象是类的一个个体,对应一个具体实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class Test { public static void main (String[] args) { Cat cat = new Cat (); cat.name = "小白" ; cat.age = 12 ; cat.color = "白色" ; } } class Cat { String name = "" ; int age = 0 ; String color = "" ; }
以上代码中对象在JVM中的存在形式如下:
在Java中创建对象的流程步骤如下:
先加载类的属性和方法信息(在方法区中加载,并且只会加载一次)
在堆中分配空间,进行默认初始化
把地址赋给对象名,即该对象名指向该对象
进行指定初始化,例如 对象名.属性名 = 值;
成员变量(属性)
概念:成员变量 = 属性 = field(字段)
属性是类的一个组成部分,一般是基本数据类型,也可以是引用类型(对象、数组)
通过对象名.属性名访问该对象的特定属性
细节:
属性的定义语法同变量定义语法一致,示例:访问修饰符 属性类型 属性名;
属性的定义类型可以是任意类型,包含基本类型和引用类型
属性如果不赋值,有默认值,规则和数组一致
成员方法
基本介绍:对于一个类而言,除了属性还有行为,在Java中对于行为,使用方法来描述。例如人类会说话,会睡觉,这就是一种行为
1 2 3 4 5 6 7 class Person { String name = "" ; int age = 18 ; public void speak () { System.out.println(this .name + "说话了" ): } }
方法调用机制分析:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class Test { public static void main (String[] args) { Person p = new Person (); int resultSum = p.getSum(10 , 20 ); System.out.println("结果为" + resultSum); } } class Person { String name = "" ; int age = 18 ; public int getSum (int num1, int num2) { int sum = num1 + num2; return sum; } }
当程序执行到方法时,就会开辟一个独立的空间(栈空间)
当方法执行完毕,或者执行到return语句时,就会返回到调用方法的地方,此时该栈空间会被销毁
返回后,继续执行方法后面的代码
当main方法(栈)执行完毕,整个程序退出
成员方法的好处:
提高代码的复用性
可以将实现的细节封装起来,供其他用户调用
成员方法的定义
1 2 3 4 public 返回数据类型 方法名 (形参列表) { 方法体; return 返回值; }
形参列表:用于接收外部调用成员方法时,传递的参数值
返回数据类型:表示成员方法输出,void表示没有返回值
方法主体:表示为了实现某一功能的代码块
return语句不是必须的
成员方法的使用细节
返回值使用细节
一个方法最多有一个返回值(要返回多个结果,可以采用集合或者数组)
返回类型可以为任意类型
如果方法要求有返回数据类型,则方法体中最后的执行语句必须是 return 值; 而且要求返回值类型必须和return的值类型一致或兼容
如果方法是void,则方法体中可以没有return语句,或者可以只写return;
方法名应遵循驼峰命名法(第一个单词的首字母小写,后面的单词的首字母必须大写),见名知意
形式参数使用细节
一个方法可以有0个参数,也可以有多个参数,中间用逗号隔开
参数类型可以为任意类型
调用带参数的方法时,一定对应着参数列表传入相同类型或兼容类型的参数
方法定义时的参数称为形式参数,简称形参;方法调用时的传入参数称为实际参数,简称实参;实参和形参的类型要一致或兼容、个数、顺序必须一致
方法调用细节
同一个类中方法的调用:直接调用即可
跨类的方法调用:例如A类中的方法调用B类中的方法,需要在A类方法中创建B类的对象,再通过 对象名.B类中的方法名 调用
成员方法传参机制
对于基本数据类型,成员方法传递的是值(值拷贝),形参内容改变,不会影响实参内容。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class MethodParameter01 { public static void main (String[] args) { int a = 10 ; int b = 20 ; AA obj = new AA (); obj.swap(a, b); System.out.println("调用swap方法后,a=" + a + " b=" + b); } } class AA { public void swap (int a, int b) { System.out.println("交换前,a=" + a + " b=" + b); int temp = a; a = b; b = temp; System.out.println("交换后,a=" + a + " b=" + b); } }
对于引用数据类型,成员方法传递的是地址(也是值拷贝,不过值是地址),形参会影响实参。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class MethodParameter02 { public static void main (String[] args) { int [] arr = {1 , 2 , 3 }; AA obj = new AA (); obj.updateArr(arr); for (int i = 0 ; i < arr.length; i++) { System.out.print(arr[i] + "\t" ); } } } class AA { public void updateArr (int [] arr) { arr[0 ] = 100 ; for (int i = 0 ; i < arr.length; i++) { System.out.print(arr[i] + "\t" ); } System.out.println(); } }
方法的递归调用 本质:方法体中自己调用自己,形成一种递归调用的形式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class Test { public static void main (String[] args) { FactorialClass factorialClass = new FactorialClass (); int result = factorialClass.factorial(5 ); System.out.println(result); } } class FactorialClass { public int factorial (int n) { if (n == 1 ) { return 1 ; } else { return factorial(n - 1 ) * n; } } }
细节:
执行一个方法时,就创建一个新的受保护的独立空间(栈空间)
方法的局部变量是独立的,不会相互影响
如果方法中使用的是引用类型变量(比如数组),就会共享该引用类型的数据
递归必须向退出递归的条件逼近,否则就会无限递归,出现栈溢出的错误
当一个方法执行完毕,或者遇到return,就会返回,遵守谁调用,就将结果返回给谁的准则,同时当方法执行完毕或者返回时,该方法也就执行完毕
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 public class MiGong { public static void main (String[] args) { int [][] map = new int [8 ][7 ]; for (int i = 0 ; i < 7 ; i++) { map[0 ][i] = 1 ; map[7 ][i] = 1 ; } for (int i = 0 ; i < 8 ; i++) { map[i][0 ] = 1 ; map[i][6 ] = 1 ; } map[3 ][1 ] = 1 ; map[3 ][2 ] = 1 ; map[2 ][2 ] = 1 ; System.out.println("初始地图:" ); for (int i = 0 ; i < map.length; i++) { for (int j = 0 ; j < map[i].length; j++) { System.out.print(map[i][j] + " " ); } System.out.println(); } T t = new T (); t.findWay(map, 1 , 1 ); System.out.println("找到路径后的地图:" ); for (int i = 0 ; i < map.length; i++) { for (int j = 0 ; j < map[i].length; j++) { System.out.print(map[i][j] + " " ); } System.out.println(); } } } class T { public boolean findWay (int [][] map, int i, int j) { if (map[6 ][5 ] == 2 ) { return true ; } else { if (map[i][j] == 0 ) { map[i][j] = 2 ; if (findWay(map, i + 1 , j)) { return true ; } else if (findWay(map, i, j + 1 )) { return true ; } else if (findWay(map, i - 1 , j)) { return true ; } else if (findWay(map, i, j - 1 )) { return true ; } else { map[i][j] = 3 ; return false ; } } else { return false ; } } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public class HanoiTower { public static void main (String[] args) { Tower tower = new Tower (); tower.move(5 , 'A' , 'B' , 'C' ); } } class Tower { public void move (int num, char curTower, char tempTower, char destTower) { if (num == 1 ) { System.out.println(curTower + "=>" + destTower); } else { move(num - 1 , curTower, destTower, tempTower); System.out.println(curTower + "=>" + destTower); move(num - 1 , tempTower, curTower, destTower); } } }
方法重载(overload) 定义:Java中允许同一个类中,多个同名方法的存在,但要求形参列表不一致
作用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class OverLoad01 { public static void main (String[] args) { MyCalculate myCalculate = new MyCalculate (); System.out.println(myCalculate.Calculate(1 , 2 )); System.out.println(myCalculate.Calculate(1.1 , 2 )); } } class MyCalculate { public int Calculate (int num1, int num2) { return num1 + num2; } public double Calculate (double num1, int num2) { return num1 + num2; } }
细节:
方法名必须一致
形参列表:必须不同(形参类型或个数或顺序,至少有一样不同,参数名无要求)
返回类型:无要求(即返回类型不是构成方法重载的要求)
可变参数 基本介绍:Java允许将同一个类中多个同名同功能但参数个数不同的方法,通过可变参数封装成一个方法
1 2 3 访问修饰符 返回类型 方法名(数据类型... 形参名) { 方法体; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class VarParameter01 { public static void main (String[] args) { Methods methods = new Methods (); System.out.println(methods.getSum(1 , 3 , 100 )); } } class Methods { public int getSum (int ... nums) { System.out.println("接收的参数个数为:" + nums.length); int sum = 0 ; for (int i = 0 ; i < nums.length; i++) { sum += nums[i]; } return sum; } }
细节:
可变参数的实参可以为0个或者任意多个
可变参数的实参可以是数组
可变参数的本质就是数组,故而使用可变参数时,就采用使用数组的语法
可变参数可以和普通类型的参数一起放在形参列表,但是必须保证可变参数在最后
一个形参列表中只能出现一个可变参数
作用域 基本概念:
在Java中,变量可分了局部和全局变量
局部变量是一般指在成员方法中定义的变量
全局变量是指在类的属性,作用域为整个类体,成员方法也能调用该变量
全局变量不赋值可直接使用,因为有默认值,局部变量必须赋值后才能使用,因为没有默认值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class Test { public static void main (String[] args) { T t = new T (); t.test(); } } class T { int num; public void test () { String str = "hello, world" ; System.out.println(num + " " + str); } }
细节:
属性(全局变量)和局部变量可以重名,使用时遵循就近原则
在同一个作用域中,比如在同一个成员方法中,有两个局部变量,就不能重名
属性伴随对象的创建而创建,伴随对象的销毁而销毁。局部变量,伴随它的代码块的执行而创建,伴随代码块的结束而销毁,即一次方法的调用
作用域范围不同
全局变量(属性):可以在本类中使用,或其他类使用(通过对象调用)
局部变量:只能在本类中对应的方法中使用
修饰符不同
全局变量(属性)可以加修饰符
局部变量不允许加修饰符
构造器 基本介绍:构造方法又叫构造器,是类的一种特殊方法,主要作用是完成对新对象的初始化
特点:
方法名和类名相同
没有返回值
在创建对象时,系统会自动调用该类的构造器完成对对象的初始化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class Constructor01 { public static void main (String[] args) { Person p1 = new Person ("Tom" , 18 ); Person p2 = new Person ("Rose" ); System.out.println("p1的属性:" + p1.name + " " + p1.age); System.out.println("p2的属性:" + p2.name); } } class Person { String name; int age; public Person (String Pname, int Page) { name = Pname; age = Page; } public Person (String Pname) { name = Pname; } }
细节:
一个类可以定义多个不同的构造器,即构造器重载
构造器名和类名要相同
构造器没有返回值
构造器时完成对象的初始化,并不是创建对象
在创建对象,系统自动调用该类的构造器
如果程序员没有定义构造器,系统会自动给类生成一个默认无参构造器
一旦定义了自己的构造器,默认构造器就被覆盖了,就不能再使用默认无参构造器,除非显示定义一下,即 public 类名() {}
对象创建流程分析 1 2 3 4 5 6 7 8 9 10 11 12 13 public class Test { public static void main (String[] args) { Person p = new Person ("小倩" , 20 ); } } class Person { int age = 90 ; String name; Person(String n, int a) { name = n; age = a; } }
以上代码执行流程分析:
首先在方法区中加载Person类信息,只加载一次
再在栈中新建一个独立的空间(用于执行main方法中的代码,称为main空间),执行到Person p = new Person(“小倩”, 20);代码时,在堆中开辟一个空间用于存放对象信息
初始化对象数据,age初始化为0,name初始化为null,然后显式初始化,将age赋值为90
再在栈中新建一个独立空间(用于执行有参构造方法),在方法区的常量池中存放字符串小倩,name赋值为存放该字符串数据的地址,age再赋值为20
此时main空间中有个对象名(对象引用)p赋值为在堆中存放该对象的地址
this 关键字 介绍:Java虚拟机会给每个对象分配 this,代表当前对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class Constructor01 { public static void main (String[] args) { Person p1 = new Person ("Tom" , 18 ); Person p2 = new Person ("Rose" ); System.out.println("p1的属性:" + p1.name + " " + p1.age); System.out.println("p2的属性:" + p2.name); } } class Person { String name; int age; public Person (String name, int age) { this .name = name; this .age = age; } public Person (String name) { this .name = name; } }
细节:
this 关键字可以用来访问本类的属性、方法、构造器
this用于区分当前类的属性和局部变量
访问成员方法的语法:this.方法名(参数列表);
访问构造器语法:this(参数列表); 注意只能在构造器中使用 但是该语法只能写在第一条语句
this不能在类定义的外部使用,只能在类定义的方法中使用
包 作用
区分相同名字得类
当类很多时,可以很好的管理类
控制访问范围(与访问修饰符有关)
基本语法
package 关键字,表示打包
com.itcz 表示包名
本质 实际上就是创建不同的文件夹来保存类文件
命名规则与规范
规则:只能包含数字、字母、下划线、小圆点,但不能以数字开头,不能是关键字或保留字
规范:一般是小写字母+小圆点,例如:com.公司名.项目名.业务模块名
使用细节
包的导入语法
1 2 3 import 包名.类名;或者 import 包名.*;
第一条用于引入该包下的特定类
第二条用于引入该包下的所有类
打包的语法
该语法必须放在Java文件的第一行中,并且每个Java文件中都只能包含一条该类型的语句
import导入语法放在打包语法之后,类定义语法直线,可以存在多条导入语句,并且无顺序要求
访问修饰符
访问级别 访问控制修饰符 同类 同包 子类 不同包
公开 public
√
√
√
√
受保护 protected
√
√
√
×
默认 没有修饰符
√
√
×
×
私有 private
√
×
×
×
使用注意事项:
修饰符可以用来修饰类中的属性,成员方法以及类
只有默认的和public才可以修饰类,并且遵循上述访问权限的特点
成员方法的访问规则和属性完全一样
封装
定义 :封装就是把抽象出的数据(属性)和对数据的操作(方法)封装在一起,数据被保护在内部,程序的其他部分只有通过被授权的操作(方法),才能对数据进行操作作用 :
隐藏实现的细节(方法),直接调用方法即可
可以在方法中对数据进行验证,保证安全合理
实现步骤 :
将属性私有化(不能直接修改属性)
提供公共的set方法,用于对属性判断并赋值
1 2 3 4 public void setXxx (类型 参数名) { 属性名 = 参数名; }
1 2 3 public XX getXxx () { retrun xx; }
set方法和构造器的组合 :
当需要使用构造器来给属性赋值时,可以在构造器方法内调用set方法,来起到验证数据的作用
继承
定义 :当多个类存在相同的属性和方法时,可以从这些类中抽象出父类,在父类中定义这些相同的属性和方法,所有的子类不需要重复定义这些属性和方法,只需要通过extends来声明继承父类即可好处 :提高代码的复用性基本语法 :
1 2 3 class 子类名 extends 父类 { }
子类会自动拥有父类定义的属性和方法
父类又叫超类、基类
子类又叫派生类
细节 :
子类继承了所有的属性和方法,非私有的属性和方法可以直接访问,但是私有的属性和方法不能在子类中直接访问,要通过公共的方法去访问
子类必须调用父类的构造器,完成父类的初始化,即使不主动调用,也会默认调用父类的无参构造器
当创建子类对象时,不管使用子类的哪个构造器,默认情况下总会去调用父类的无参构造器,如果父类没有提供无参构造器,则必须在子类的构造器中用super去指定使用父类的哪个构造器完成对父类的初始化工作,否则编译不会通过
如果希望指定去调用父类的某个构造器,则显式调用一下
super在使用时,需要放在子类构造器的第一行
super() 和 this() 都只能放在构造器第一行,因此这两个方法不能共存于一个构造器
Java所有类都是Object类的子类
父类构造器的调用不限于直接父类,将一直往上追溯直到Object类(顶级父类)
子类最多只能继承一个父类,即Java中是单继承机制,可以通过A继承B,B继承C 来实现A类继承B类和C类
不能滥用继承,子类与父类之间必须满足子类属于父类的范围的逻辑关系(例如父类是动物,子类是猫)
继承的本质 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class Test { public static void main (String[] args) { Son son = new Son (); System.out.println(son.age); } } class GrandPa { String name = "大头爷爷" ; String hobby = "旅游" ; } class Father extends GrandPa { String name = "大头爸爸" ; int age = 39 ; } class Son extends Father { String name = "大头儿子" ; }
上述代码在Jvm内存的存在形式如下:
加载流程:
先加载类信息,包括类之间继承的关系
在堆中开辟空间,基本数据类型数据直接存储在堆中,字符串类型数据存储在方法区的常量池中,该数据对应的地址则存放到堆中
栈中对象名指向该对象在堆中地址
super 关键字
基本介绍 :super代表父类的引用,用于访问父类的属性、方法、构造器基本语法 :
只能放在构造器的第一句,只能出现一次
使用细节 :
当子类中有和父类中的成员(属性和方法)重名时,为了访问父类的成员,必须通过super。如果没有重名,使用super、this、直接访问是一样的结果
当使用super调用方法或属性时,会直接跳过查找子类中的方法或属性,直接去父类进行查找,未找到再查找父类的父类,直到找到Object
super的访问不限于直接父类,如果爷爷类和本类中有同名成员,也可以使用super去访问爷爷类的成员;如果多个基类中都有同名成员,使用super访问遵循就近原则
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public class Test { public static void main (String[] args) { Son son = new Son (); son.test(); } } class GrandPa { String name = "大头爷爷" ; String hobby = "旅游" ; } class Father extends GrandPa { String name = "大头爸爸" ; int age = 39 ; } class Son extends Father { String name = "大头儿子" ; public void test () { System.out.println(super .hobby); } }
方法重写 override
定义 :方法重写就是子类有一个方法,和父类的某个方法的名称、放回类型、形参列表完全一样,那么这个子类的方法久重写了父类的方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class Test { public static void main (String[] args) { Dog dog = new Dog (); dog.cry(); } } class Animal { public void cry () { System.out.println("动物叫唤..." ); } } class Dog extends Animal { public void cry () { System.out.println("小狗汪汪叫..." ); } }
使用细节
子类的方法的形参列表和方法名称,要和父类方法的形参列表和名称完全一样
子类方法的返回类型要和父类方法的返回类型一样,或者是父类返回类型的子类,比如父类为Object,子类方法返回类型是String
子类方法不能缩小父类方法的访问权限(public > protected > 默认 > private)
Object 类详解 equals 方法
功能 :只能判断引用类型,默认判断的是地址是否相等,子类可以重写该方法,用于判断内容是否相等(例如:Interger, String)与 == 的区别 :
== 是比较运算符,可以用于比较基本数据类型和引用数据类型
== 如果用于基本数据类型,则判断值是否相等
== 如果用于引用数据类型,则判断地址是否相等,即是否为同一个对象
Object 中的 equals 方法源码
1 2 3 public boolean equals (Object obj) { return (this == obj); }
String 中的 equals 方法源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public boolean equals (Object anObject) { if (this == anObject) { return true ; } if (anObject instanceof String) { String anotherString = (String)anObject; int n = value.length; if (n == anotherString.value.length) { char v1[] = value; char v2[] = anotherString.value; int i = 0 ; while (n-- != 0 ) { if (v1[i] != v2[i]) return false ; i++; } return true ; } } return false ; }
Interger 中的 equals 方法源码
1 2 3 4 5 6 7 8 9 10 public boolean equals (Object obj) { if (obj instanceof Integer) { return value == ((Integer)obj).intValue(); } return false ; }
hashCode 方法
功能 :通过对象的地址计算出hash值,然后返回hash值。主要是提高具有hash结构的容器的效率细节 :
若两个引用都指向同一个地址,即同一个对象,则hash值是一样的
若两个引用指向不同的地址,则hash值是不一样的
hash值是根据地址计算得来,但不能完全将hash值等价于地址
toString 方法
功能 :默认返回 全类名 + @ + hash值的十六进制
1 2 3 4 5 public String toString () { return getClass().getName() + "@" + Integer.toHexString(hashCode()); }
细节 :
子类可以重写Object的toString方法,一般是输出对象的属性值
直接输出对象时,toString方法会被默认调用
finalize 方法
功能 :当对象被回收时,系统自动调用该对象的finalize方法。子类可重写该方法,做一些释放资源的操作细节 :
当某个对象没有任何引用时,则JVM就认为这个对象是一个垃圾对象,就会使用垃圾回收器销毁该对象,在销毁该对象前,会先调用finalize方法
垃圾回收器的调用,是由系统来决定的,也可以通过System.gc()方法主动触发垃圾回收器
多态
定义 :方法或对象具有多种形态。是面向对象的第三大特征,多态是建立再封装和继承基础之上的。多态的具体体现 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public class Test { public static void main (String[] args) { Dog dog = new Dog (); dog.cry(); dog.cry("小花" ); System.out.println("======" ); Animal animal = new Animal (); animal.cry(); dog.cry(); } } class Animal { public void cry () { System.out.println("动物叫唤..." ); } } class Dog extends Animal { public void cry () { System.out.println("小狗汪汪叫..." ); } public void cry (String name) { System.out.println(name + "汪汪叫..." ); } }
对象的多态:对象的编译类型和运行类型可以不一致,编译类型在定义对象时就确定并且无法改变,运行类型可以变化。编译类型看定义时 = 号的左边,运行类型看 = 号的右边
向上转型 :
本质:父类的引用指向了子类的对象
语法:父类类型 引用名 = new 子类类型();
特点:
1)可以调用父类的所有成员(需遵循访问权限)
2)不能调用子类特定的方法,因为在编译阶段,调用成员需要通过编译类型决定
3)运行时需看运行类型的具体体现。即调用方法时,按照从子类(运行类型)开始查找
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class Test { public static void main (String[] args) { Animal animal = new Dog (); animal.cry(); } } class Animal { public void cry () { System.out.println("动物叫唤..." ); } } class Dog extends Animal { public void cry () { System.out.println("小狗汪汪叫..." ); } public void eatBone () { System.out.println("小狗吃骨头..." ); } }
向下转型 :
语法:子类类型 引用名 = (子类类型)父类引用;
只能强制转父类的引用,不能强转父类的对象
要求父类的引用必须指向的是当前目标类型的对象
可以调用子类类型中的所有成员
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public class Test { public static void main (String[] args) { Animal animal = new Dog (); animal.cry(); Dog dog = (Dog) animal; dog.eatBone(); } } class Animal { public void cry () { System.out.println("动物叫唤..." ); } } class Dog extends Animal { public void cry () { System.out.println("小狗汪汪叫..." ); } public void eatBone () { System.out.println("小狗吃骨头..." ); } }
使用细节 :
属性没有重写一说,属性的调用看的是编译类型
instanceof 比较操作符,用于判断对象的运行类型是否为某个类型或某个类型的子类型
动态绑定机制
当调用对象方法的时候,该方法会和该对象的内存地址(运行类型)绑定
当调用对象属性时,没有动态绑定机制,哪里声明哪里使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public class Test { public static void main (String[] args) { A a = new B (); System.out.println(a.sum()); System.out.println(a.sum1()); } } class A { private int i = 20 ; public int sum () { return getI() + 10 ; } public int sum1 () { return i + 20 ; } public int getI () { return i; } } class B extends A { private int i = 10 ; public int getI () { return i; } }
多态数组 数组定义类型为父类类型,存储实际元素类型为子类类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 public class Test { public static void main (String[] args) { Person[] persons = new Person [3 ]; persons[0 ] = new Person ("tom" , 30 ); persons[1 ] = new Student ("lisi" , 18 , 98.9 ); persons[2 ] = new Teacher ("zhangsan" , 40 , 10000 ); for (int i = 0 ; i < persons.length; i++) { System.out.println(persons[i].show()); } for (int i = 0 ; i < persons.length; i++) { if (persons[i] instanceof Student) { System.out.println(((Student)persons[i]).study()); } else if (persons[i] instanceof Teacher) { System.out.println(((Teacher)persons[i]).teach()); } } } } class Person { private String name; private int age; public Person (String name, int age) { this .name = name; this .age = age; } public String show () { return "name=" + this .name + " age=" + this .age; } public String getName () { return this .name; } } class Student extends Person { private double score; public Student (String name, int age, double score) { super (name, age); this .score = score; } @Override public String show () { return super .show() + " score=" + this .score; } public String study () { return super .getName() + "正在学习Java" ; } } class Teacher extends Person { private double salary; public Teacher (String name, int age, double salary) { super (name, age); this .salary = salary; } @Override public String show () { return super .show() + " salary=" + this .salary; } public String teach () { return super .getName() + "正在教授Java" ; } }
多态参数 方法形式参数定义为父类类型,实际参数允许为子类类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 public class Test { public static void main (String[] args) { Worker worker = new Worker ("tom" , 2000 ); Manager manager = new Manager ("zhangsan" , 6000 , 20000 ); TestMethod testMethod = new TestMethod (); testMethod.testGetAnnual(worker); testMethod.testGetAnnual(manager); testMethod.testWork(worker); testMethod.testWork(manager); } } class TestMethod { public void testGetAnnual (Employee e) { System.out.println(e.getAnnual()); } public void testWork (Employee e) { if (e instanceof Worker) { ((Worker) e).work(); } else if (e instanceof Manager) { ((Manager) e).manage(); } } } class Employee { private String name; private double salary; public Employee (String name, double salary) { this .name = name; this .salary = salary; } public String getName () { return name; } public void setName (String name) { this .name = name; } public double getSalary () { return salary; } public void setSalary (double salary) { this .salary = salary; } public double getAnnual () { return 12 * this .salary; } } class Worker extends Employee { public Worker (String name, double salary) { super (name, salary); } public void work () { System.out.println("工人 is working" ); } @Override public double getAnnual () { return super .getAnnual(); } } class Manager extends Employee { private double bonus; public Manager (String name, double salary, double bonus) { super (name, salary); this .bonus = bonus; } public void manage () { System.out.println("经理 is managing" ); } public double getBonus () { return bonus; } public void setBonus (double bonus) { this .bonus = bonus; } @Override public double getAnnual () { return super .getAnnual() + this .bonus; } }
类变量
定义 :类变量又叫做静态变量/静态属性,是该类的所有对象共享的变量,任何一个该类的对象去访问它时,取到的都是相同的值,同样任何一个该类的对象去修改它时,修改的也是同一个变量。
1 2 3 访问修饰符 static 数据类型 变量名; 或者 static 访问修饰符 数据类型 变量名;
1 2 3 类名.类变量名 (说明:类变量是随着类的加载而创建,所以即使没有创建对象实例也可以访问) 或 对象名.类变量名
静态变量的访问修饰符的访问权限和普通属性一致
特点 :静态变量会被该类的所有对象实例共享内存布局 :首先栈中的对象引用指向堆中对象的地址,其次堆中的对象的变量名又会指向堆中的静态变量所在的地址,下图就是Child类中静态变量count在JVM内存中的布局(jdk8之后,之前的话静态变量存放在方法区)
细节 :
当需要让某个类的所有对象都共享一个变量时,可以考虑使用类变量
用static修饰的变量称为静态变量/类变量,未用static修饰的变量则称为普通变量/普通成员变量/非静态变量
类变量是在类加载时就初始化了,即使未创建对象,只要类加载了就可使用类变量
类变量的生命周期是随类的加载开始,随着类的消亡而销毁
类方法
定义 :类中的方法用static修饰后称为静态方法,又称类方法
1 2 3 访问修饰符 static 数据返回类型 方法名() {} 或者 static 访问修饰符 数据返回类型 方法名() {}
1 2 3 类名.类方法名(); 或者 对象名.类方法名();
前提是满足访问修饰符的访问权限
使用的最佳场景 :当不需要创建对象就可以访问访问方法时,就可以使用类方法,例如JDK源码中的Array和Collection等类中就存在大量静态方法,可以直接通过类名就可以使用其中的方阿飞细节 :
类方法和普通方法是都是随着类的加载而加载,将方法的结构信息存储在方法区
类方法可以用类名和对象名调用,普通方法不可通过类名调用
类方法中不可使用和对象有关的关键字,比如this和super。普通方法可以使用
类方法只能直接访问本类的类方法和类变量,而普通方法既可以直接访问本类的非静态成员,也可以直接访问本类的静态成员。但是类方法中可以通过创建对象,用对象名.方法名访问某个类的非静态方法
代码块
定义 :代码块又称初始化块,属于类中的成员,类似于方法,将逻辑语句封装在方法体中,通过{}包围起来。但是和方法不同,它没有方法名,没有返回,没有参数,只有方法体,而且不用通过对象或类显式调用,而是加载类或创建对象时隐式调用
说明:
修饰符可选,只能写static
static修饰的代码块称为静态代码块,未修饰的称为普通代码块/非静态代码块
逻辑语句可以是任何语句
最后的分号可选
细节 :
静态代码块在类加载时只会执行一次,代码块则是在每次创建对象时都会执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class SmallChange { public static void main (String[] args) { A a1 = new A (); A a2 = new A (); } } class A { static { System.out.println("A 类的静态代码块被执行" ); } { System.out.println("A 类的代码块被执行" ); } }
类加载的时机:
当创建对象实例时会加载类
创建子类对象实例时,会先加载父类,再加载子类
使用子类的静态成员时,也会先加载父类,再加载子类
使用类的静态成员时,普通代码块不会执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class SmallChange { public static void main (String[] args) { System.out.println(A.n1); } } class A { public static int n1; static { System.out.println("A 类的静态代码块被执行" ); } { System.out.println("A 类的代码块被执行" ); } }
创建一个对象时,类中初始化代码执行顺序:
先执行静态代码块和静态属性初始化(注意:两者调用优先级一致,若有多个静态代码块和多个静态变量初始化,则按定义顺序执行)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class SmallChange { public static void main (String[] args) { A a = new A (); } } class A { static { System.out.println("A 类的静态代码块被执行" ); } public static int n1 = getN1(); public static int getN1 () { System.out.println("A 类的静态属性初始化被执行" ); return 200 ; } }
- 再执行普通代码块和普通属性初始化(注意:两者调用优先级一致,若有多个普通代码块和多个普通属性初始化,则按定义顺序执行)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class SmallChange { public static void main (String[] args) { A a = new A (); } } class A { static { System.out.println("A 类的静态代码块被执行" ); } private int n2 = getN2(); { System.out.println("A 类的普通代码块被执行" ); } private static int n1 = getN1(); public static int getN1 () { System.out.println("A 类的静态属性初始化被执行" ); return 200 ; } public int getN2 () { System.out.println("A 类的普通属性初始化被执行" ); return 100 ; } }
- 最后执行构造方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public class SmallChange { public static void main (String[] args) { A a = new A (); } } class A { public A () { System.out.println("A 类的无参构造器被执行" ); } static { System.out.println("A 类的静态代码块被执行" ); } private int n2 = getN2(); { System.out.println("A 类的普通代码块被执行" ); } private static int n1 = getN1(); public static int getN1 () { System.out.println("A 类的静态属性初始化被执行" ); return 200 ; } public int getN2 () { System.out.println("A 类的普通属性初始化被执行" ); return 100 ; } }
构造器的最前面隐藏了super()和调用普通代码块,故而会先调用父类的构造方法,而父类又会先调用父类的父类的构造方法,一直到Object类为止
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public class SmallChange { public static void main (String[] args) { B b = new B (); } } class A { public A () { System.out.println("A 类的无参构造器被执行" ); } { System.out.println("A 类的普通代码块被执行" ); } } class B extends A { { System.out.println("B 类的普通代码块被执行" ); } public B () { System.out.println("B 类的无参构造器被执行" ); } }
当一个类继承父类,创建子类对象时,初始化代码执行顺序:
父类的静态代码块和静态属性(优先级一样,按定义顺序执行)
子类的静态代码块和静态属性(优先级一样,按定义顺序执行)
父类的普通代码块和普通属性初始化(优先级一样,按定义顺序执行)
父类的构造方法
子类的普通代码块和普通属性初始化(优先级一样,按定义顺序执行)
子类的构造方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 public class SmallChange { public static void main (String[] args) { B b = new B (); } } class A { static { System.out.println("A 类的静态代码块被执行" ); } private int n2 = getN2(); { System.out.println("A 类的普通代码块被执行" ); } private static int n1 = getN1(); public static int getN1 () { System.out.println("A 类的静态属性初始化被执行" ); return 200 ; } public int getN2 () { System.out.println("A 类的普通属性初始化被执行" ); return 100 ; } public A () { System.out.println("B 类的无参构造器被执行" ); } } class B extends A { static { System.out.println("B 类的静态代码块被执行" ); } { System.out.println("B 类的普通代码块被执行" ); } private int n3 = getN3(); private static int n4 = getN4(); public static int getN4 () { System.out.println("B 类的静态属性初始化被执行" ); return 200 ; } public int getN3 () { System.out.println("B 类的普通属性初始化被执行" ); return 100 ; } public B () { System.out.println("B 类的无参构造器被执行" ); } }
静态代码块只能直接调用本类的静态成员,普通代码块可以直接调用本类的任意成员
final 关键字
功能 :被final修饰的类不能被继承,被final修饰的方法不可以被重写,被final修饰的属性/变量不可以被二次修改,但是允许初始化细节 :
final修饰的属性又叫做常量,一般用XXX_XXX_XXX来命名
final修改的属性在定义时,必须赋初值,并且以后都不能被二次修改,赋值方式有如下3种:
定义时赋值,例如:public final double TAX_RATE = 0.08;
在构造器中赋初始值
在代码块中赋初始值
如果final修饰的属性是静态的,则初始化的位置只能为以下两种:
定义时赋值,例如:public static final double TAX_RATE = 0.08;
在静态代码中赋初始值
1 2 3 4 5 6 7 8 9 10 11 12 13 public class SmallChange { public static void main (String[] args) { A a = new A (); } } class A { public static final double TAX_RATE1 = 0.08 ; public static final double TAX_RATE2; static { TAX_RATE2 = 0.09 ; } }
因为静态属性在类加载时就会被初始化,而构造器则是在创建对象时才会被调用,故而无法在构造器中赋初始值
final类不能被继承,但是可以实例化对象
如果类不是final类,但是含有final方法,则该方法虽然不能被重写,但是可以被继承
当一个类被修饰为final类时,它其中的方法没必要用final修饰
final不能修饰构造方法
final和static往往搭配使用,效率更高。因为不会导致类加载,底层编译器做了优化处理
1 2 3 4 5 6 7 8 9 10 11 12 public class SmallChange { public static void main (String[] args) { System.out.println(A.TAX_RATE); } } class A { public static final double TAX_RATE = 0.08 ; static { System.out.println("静态代码块被执行" ); } }
包装类(Integer、Double、Float、Boolean等)都是final类,String也是final类
抽象类
定义 :当父类中的某些方法需要声明,但是不确定如何实现,可以将其声明为抽象方法,那么这个类就是抽象类
1 2 3 4 5 访问修饰符 abstract class 类名 { 访问修饰符 abstract 返回类型 方法名(参数列表); }
细节 :
抽象类是不可以实例化对象的
抽象类中不一定有抽象方法,但是有抽象方法的类一定是抽象类。抽象类中还可以有非抽象方法
abstract 只能修饰类和方法,不能修饰属性等
抽象类还是类,可以有类中拥有的所有成员
抽象方法不能有方法体,即不能实现
如果一个类继承了抽象类,则它必须实现抽象类的所有抽象方法,除非它自己也声明为abstract类
private、static、final不能与abstract组合修饰方法,因为前三者修饰的方法都不允许被重写,而abstract修饰的方法是需要被重写的
接口
定义 :接口就是将一些没有实现的方法封装到一起,直到某个类要使用的时候,再根据具体情况实现这些方法
1 2 3 4 5 6 7 8 9 10 11 访问修饰符 interface 接口名 { } 访问修饰符 class implements 接口名 { }
JDK7之前接口中只有没有方法体的方法
JDK8之后允许接口中有静态方法(必须带有static关键字),默认方法(必须带有default关键字),即允许接口中可以有方法的具体实现
接口中的抽象方法可以省略abstract关键字
细节 :
接口不能被实例化
接口中所有方法都是public方法,接口中的抽象方法,可不用abstract修饰
一个普通类实现接口,就必须实现该接口的所有抽象方法
抽象类实现接口,可以不用实现接口的抽象方法
一个类同时可以实现多个接口
接口中的属性只能是final的,而且是public static final修饰的。例如:int a = 1; 实际上是 public static final int a = 1;
接口中属性的访问形式:接口名.属性名
一个接口不能继承其他类,但是可以继承多个别的接口
接口的修饰符只能是public和默认
实现接口和继承类的区别 :
接口和继承解决的问题不同
继承的价值在于解决代码的复用性和可维护性
接口的价值在于设计好各种规范,让其他类去实现这些方法。即更加灵活
接口比继承更加灵活,继承满足is - a关系,而接口满足like - a关系
接口从一定程度上实现了代码解耦(接口规范性+动态绑定机制)
接口的多态特性 :
多态参数:接口引用可以指向实现该接口的类的对象实例
多态数组:接口数组中的每个元素可以指向实现该接口的类的对象实例
以上两种和类的多态特性一致
多态传递:如果一个接口B继承了存在抽象方法的接口A,类C实现了接口B,那么类C必须实现接口A中的抽象方法,即接口之间存在多态传递机制
Java8中的接口新特性 :接口中除了可以定义全局常量和抽象方法之外,还可以定义静态方法和默认方法
接口中定义的静态方法只能通过接口名.方法名去调用
只能通过实现接口的类的对象去调用接口的默认方法,如果实现类重写了接口中的默认方法,那么调用时,调用的是重写后的方法
如果实现类继承了父类,而父类和接口中有同名同参数的默认方法,那么实现类(子类)在没有重写此方法的情况下,默认调用的是父类中的方法(类优先原则)
如果实现类实现了多个接口,而多个接口中定义了同名同参数的默认方法,那么在实现类没有重写此方法的情况下,会报错(接口冲突),这就必须在实现类中重写此方法
在通过 接口名.super.方法名 在实现类中调用接口中的已经被重写的方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 public class Test { public static void main (String[] args) { IA.method1(); SubClass subClass = new SubClass (); subClass.method2(); subClass.method3(); } } class SubClass extends SuperClass implements IA , IB { @Override public void method2 () { System.out.println("实现类中的默认方法被调用" ); IA.super .method2(); IB.super .method2(); } } class SuperClass { public void method3 () { System.out.println("父类中的默认方法被调用" ); } } interface IA { public static void method1 () { System.out.println("接口IA中的静态方法被调用" ); } public default void method2 () { System.out.println("接口IA中的默认方法被调用" ); } default void method3 () { System.out.println("接口IA中的默认方法被调用" ); } } interface IB { public default void method2 () { System.out.println("接口IB中的默认方法被调用" ); } }
内部类
定义 :一个类的内部又完整的嵌套了另一个类结构。被嵌套的类称为内部类,嵌套其他类的类称为外部类(类的五大成员有:属性、方法、构造器、代码块以及内部类)内部类最大特点是可以直接访问私有属性,并且可以体现类与类之间的包含关系
1 2 3 4 5 6 7 8 9 10 11 12 public class 类名 { calss 类名 { } } class 类名 { }
内部类的分类 :
定义在外部类局部位置上(比如方法内)
定义在外部类的成员位置上
成员内部类(没用static修饰)
静态内部类(使用static修饰)
局部内部类
定义 :局部内部类定义在外部类的局部位置,比如方法中,并且有类名细节 :
局部内部类可以直接访问外部类的所有成员,包含私有的属性和方法
不能添加访问修饰符,因为它的地位就是一个局部变量。局部变量是不能使用访问修饰符的,但是可以使用final修饰,因为局部变量可以使用final修饰,这是该类就不能被继承
它的作用域仅仅是指在定义它的方法或者代码块中
可以在定义它的方法或者代码块中创建它的对象,这样就可以访问它其中的属性和方法
外部其他类不能访问局部内部类的成员
如果外部类和局部内部类的成员重名,访问时遵循就近原则,如果要访问外部类的成员,使用 外部类名.this.成员名 进行访问
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 public class LocalInnerClass { public static void main (String[] args) { Outer outer = new Outer (); outer.f1(); System.out.println("outer的hashCode:" + outer); } } class Outer { private int n1 = 1 ; private void m1 () { System.out.println("Outer m1()方法被调用" ); } { class Inner2 { } } public void f1 () { class Inner1 { private int n1 = 2 ; public void f2 () { System.out.println("局部内部类的n1=" + n1); System.out.println("外部类的n1=" + Outer.this .n1); System.out.println("Outer.this的hashCode值:" + Outer.this ); m1(); } } Inner1 inner = new Inner1 (); inner.f2(); } }
匿名内部类
定义 :匿名内部类定义在外部类的局部位置,比如方法中,并且没有类名
基于接口的匿名内部类 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 public class AnonymousInnerClass { public static void main (String[] args) { A a = new A (); a.method(); } } class A { private int n1 = 0 ; public void method () { IA tiger = new IA () { @Override public void cry () { System.out.println("老虎叫唤...." ); } }; tiger.cry(); System.out.println("tiger的运行类型:" + tiger.getClass()); } } interface IA { public void cry () ; }
基于类的匿名内部类 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 public class AnonymousInnerClass { public static void main (String[] args) { A a = new A (); a.method(); } } class A { public void method () { Father son = new Father ("张三" ) { @Override public void speak () { System.out.println(super .getName() + "的speak方法被调用" ); } }; son.speak(); System.out.println("son的运行类型:" + son.getClass()); } } class Father { private String name; public Father (String name) { this .name = name; System.out.println("name = " + name); } public void speak () { } public String getName () { return this .name; } }
细节 :
匿名内部类从语法上看既有定义类的特征,又有创建类的特征
由于匿名内部类会返回一个对象,故而可以不接收该对象,直接调用该匿名内部类的成员
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class AnonymousInnerClass { public static void main (String[] args) { A a = new A (); a.method(); } } class A { public void method () { new Father ("张三" ) { @Override public void speak (String str) { System.out.println("匿名内部类的speak方法被调用,接收的信息为" + str); } }.speak("hello" ); } } class Father { public Father (String name) { System.out.println("name = " + name); } public void speak (String str) {} }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public class AnonymousInnerClass { public static void main (String[] args) { A a = new A (); a.method(); } } class A { private int n1 = 0 ; public void method () { new Father ("张三" ) { @Override public void speak (String str) { System.out.println("n1 = " + n1); System.out.println("匿名内部类的speak方法被调用,接收的信息为" + str); } }.speak("hello" ); } } class Father { public Father (String name) { System.out.println("name = " + name); } public void speak (String str) {} }
作用域仅仅在定义它的方法或代码块中
不能添加访问修饰符,因为它的低位就是要给局部变量
外部其他类不可以访问匿名内部类,因为匿名内部类只是方法或者代码块的局部变量
如果外部类和匿名内部类的成员重名时,匿名内部类访问这些成员的时,默认遵循就近原则,如果想要访问外部类的成员,则可以使用 外部类名.this.成员名 进行访问
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public class AnonymousInnerClass { public static void main (String[] args) { A a = new A (); a.method(); System.out.println("a的hashCode值为:" + a); } } class A { private int n1 = 0 ; public void method () { new Father ("张三" ) { private int n1 = 1 ; @Override public void speak (String str) { System.out.println("匿名内部类的n1 = " + n1); System.out.println("外部类的n1 = " + A.this .n1); System.out.println("A.this的hashCode值为:" + A.this ); System.out.println("匿名内部类的speak方法被调用,接收的信息为" + str); } }.speak("hello" ); } } class Father { public Father (String name) { System.out.println("name = " + name); } public void speak (String str) {} }
匿名内部类的最佳实践 :将匿名内部类作为实参进行传递
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class AnonymousInnerClass { public static void main (String[] args) { f1(new Animal () { @Override public void eat () { System.out.println("小狗吃骨头" ); } }); f1(new Dog ()); } public static void f1 (Animal animal) { animal.eat(); } } interface Animal { void eat () ; } class Dog implements Animal { @Override public void eat () { System.out.println("小狗吃骨头" ); } }
Lambda 表达式
作用 :简化使用匿名内部类的书写
由于匿名内部类的对象只会使用一次,故而可以省略创建对象的复杂写法,强调实现接口时重写方法的逻辑,进而简化匿名内部类的书写语法
细节 :
Lambda 表达式只能用来简化函数式接口的匿名内部类的写法,函数式接口:有且只有一个抽象方法的接口(不能是抽象类)称为函数式接口,接口上方可以添加 @FunctionalInterface 注解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 public class AnonymousInnerClass { public static void main (String[] args) { f1(new Animal () { @Override public void eat () { System.out.println("小狗吃骨头" ); } }); f1(new Dog ()); Animal animal = () -> { System.out.println("小狗吃骨头" ); }; f1(animal); f1(() -> { System.out.println("小猫吃鱼" ); }); } public static void f1 (Animal animal) { animal.eat(); } } @FunctionalInterface interface Animal { void eat () ; } class Dog implements Animal { @Override public void eat () { System.out.println("小狗吃骨头" ); } }
Lambda 表达式满足以下条件可以继续省略
参数类型可以直接不写
如果只有一个参数,参数类型可以省略,同时()也可以省略
如果Lambda表达式的方法体只有一行,大括号,分号,return都可以省略不写,但是需要同时省略
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import java.util.Arrays;import java.util.Comparator;public class AnonymousInnerClass01 { public static void main (String[] args) { Integer[] arr = {2 , 1 , 4 , -1 , 2 }; Arrays.sort(arr, (o1, o2) -> o1 - o2); System.out.println(Arrays.toString(arr)); } }
成员内部类
定义 :定义在外部类的成员位置上,并且没有static修饰
1 2 3 4 5 6 7 public class 类名 { calss 类名 { } }
细节 :
可以直接访问外部类的所有成员,包括私有的成员
可以使用所有的访问修饰符,因为它是类的一个成员
作用域和外部类的其他成员一样,为整个外部类体
外部类可以在成员方法中创建成员内部类的对象,再通过该对象访问成员内部类的成员
外部其他类访问成员内部类成员的方式
方式一:通过在外部其他类中创建成员内部类的对象去访问该类的成员
方式二:通过在外部其他类调用外部类提供的创建成员内部类的对象的方法去获取到该类的对象,再通过对象去访问该类的成员
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 public class MemberInnerClass { public static void main (String[] args) { Outer outer = new Outer ("lisi" ); Outer.Inner inner = outer.new Inner (); inner.show(); Outer.Inner innerInstance = outer.getInnerInstance(); innerInstance.show(); } } class Outer { private String name; public Outer (String name) { this .name = name; } public class Inner { public void show () { System.out.println("外部类name=" + name); } } public String getName () { return name; } public void setName (String name) { this .name = name; } public Outer.Inner getInnerInstance () { return new Inner (); } }
如果成员内部类的成员和外部类的成员重名,在成员内部类中访问该成员,会遵循就近原则,可以使用 外部类名.this.成员名 访问外部类的成员
静态内部类
定义 :定义在外部类的成员位置上,并且没有static修饰
1 2 3 4 5 6 7 public class 类名 { static calss 类名 { } }
细节:
可以直接访问外部类的所有静态成员,包括私有成员,但是不能直接访问非静态成员,可以通过创建外部类的对象去访问非静态的成员
可以添加任意的访问修饰符,因为它的地位是类的一个成员
作用域和外部类的其他成员一样,为整个外部类体
外部类可以在成员方法中创建静态内部类的对象,再通过该对象访问静态内部类的成员
外部其他类访问静态内部类的方式
方式一:通过在外部其他类中创建成员内部类的对象去访问该类的成员
方式二:通过在外部其他类调用外部类提供的创建成员内部类的对象的方法去获取到该类的对象,再通过对象去访问该类的成员
方式三:在外部其他类中通过 外部类名.创建内部类的对象的静态方法名 去获取到该类的对象,再通过对象去访问该类的成员
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 public class StaticInnerClass { public static void main (String[] args) { Outer outer = new Outer ("lisi" ); Outer.Inner inner = new Outer .Inner(); inner.show(); Outer.Inner innerInstance1 = outer.getInnerInstance1(); innerInstance1.show(); Outer.Inner innerInstance2 = Outer.getInnerInstance2(); innerInstance2.show(); } } class Outer { private static String name; public Outer (String name) { Outer.name = name; } public static class Inner { public void show () { System.out.println("外部类name=" + name); } } public String getName () { return name; } public void setName (String name) { Outer.name = name; } public Outer.Inner getInnerInstance1 () { return new Inner (); } public static Outer.Inner getInnerInstance2 () { return new Inner (); } }
如果成员内部类的成员和外部类的静态成员重名,在成员内部类中访问该成员,会遵循就近原则,可以使用 外部类名.静态成员名 访问外部类的静态成员
枚举
定义 :枚举是一种特殊的类,里面包含一组有限的特定的对象实现方式 :
自定义类实现枚举
实现步骤:
不提供set方法,防止对象属性被修改,因为枚举对象的值通常为只读类型
对枚举对象/属性使用 final + static 共同修饰,这样可以防止类加载
枚举对象名通常全部大写,这是常量的命名规范
将该类的构造器私有化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 public class EnumTest01 { public static void main (String[] args) { System.out.println(Season.SPRING); System.out.println(Season.WINTER); } } class Season { private String name; private String des; public final static Season SPRING = new Season ("春天" , "温暖" ); public final static Season SUMMER = new Season ("夏天" , "炎热" ); public final static Season AUTUMN = new Season ("秋天" , "凉爽" ); public final static Season WINTER = new Season ("冬天" , "寒冷" ); private Season (String name, String des) { this .name = name; this .des = des; } public String getName () { return name; } public String getDes () { return des; } @Override public String toString () { return "Season{" + "name='" + name + '\'' + ", des='" + des + '\'' + '}' ; } }
使用enum 关键字实现枚举
实现步骤 :
使用 enum 关键字 替代 class 关键字
原来的定义常量的语法改为常量名(实参列表)
如果有多个常量(对象),直接使用,号分隔
如果使用enum 关键字来实现枚举,要求将定义常量(对象)的语句写在第一句
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public class EnumTest02 { public static void main (String[] args) { System.out.println(EnumSeason.SPRING); System.out.println(EnumSeason.WINTER); } } enum EnumSeason { SPRING("春天" , "温暖" ), SUMMER("夏天" , "炎热" ), AUTUMN("秋天" , "凉爽" ), WINTER("冬天" , "寒冷" ); private String name; private String des; EnumSeason(String name, String des) { this .name = name; this .des = des; } public String getName () { return name; } public String getDes () { return des; } @Override public String toString () { return "Season{" + "name='" + this .getName() + '\'' + ", des='" + this .getDes() + '\'' + '}' ; } }
细节 :
当使用enum 关键字开发枚举类时,默认会继承Enum类,而且该枚举类是一个final类,可以使用javap工具反编译证明,例如上述代码反编译结果如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 public class EnumTest02 { public static void main (String[] args) { System.out.println(EnumSeason.SPRING); System.out.println(EnumSeason.SPRING.name()); System.out.println(EnumSeason.SPRING.ordinal()); EnumSeason[] enumSeasons = EnumSeason.values(); for (EnumSeason i : enumSeasons) { System.out.println(i); } EnumSeason summer = EnumSeason.valueOf("SUMMER" ); System.out.println(summer); System.out.println(EnumSeason.SPRING.compareTo(EnumSeason.SUMMER)); } } enum EnumSeason { SPRING("春天" , "温暖" ), SUMMER("夏天" , "炎热" ), AUTUMN("秋天" , "凉爽" ), WINTER("冬天" , "寒冷" ); private String name; private String des; EnumSeason(String name, String des) { this .name = name; this .des = des; } public String getName () { return name; } public String getDes () { return des; } }
注解
定义 :注解也被称为元数据,用于解释包、类、方法、属性、构造器、局部变量等数据信息。和注释一样,注解不影响程序逻辑,但是注解可以被编译或运行,相当于嵌入在代码中的补充信息JDK中常用的基本注解 :
@Override:限定于某个方法,用于标记该方法重写了父类的方法
@Deprecated:用于表示某个程序元素(类、方法等)已过时
@SuppressWarning{“”}:抑制编译器警告,在双引号中添加相应的字符串,可以抑制对应的警告。它起作用的地方和它放置的位置有关,在某个语句上就抑制该语句的警告,在方法和类等位置同理
@interface 并不是表示接口,而是表示注解
@Target 是元注解,它是修饰注解的注解
1 2 3 4 5 @Target(ElementType.METHOD) @Retention(RetentionPolicy.SOURCE) public @interface Override {}
自定义注解 :
1 2 3 public @interface 注解名 { String value default "hello" ; }
内部定义成员,通常使用value进行接收
可以指定成员的默认值,使用default定义
如果自定义注解没有成员,表明此注解为一个标识作用
如果注解有成员,那么使用注解时,必须指明成员的值
Java8中注解的新特性 :
可重复性:在自定义注解上声明@Repeatable元注解,并且声明成员值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @Repeatable(MyAnnotations.class) public @interface MyAnnotation { String value; } public @interface MyAnnotations { MyAnnotation[] value; } public class Test { @MyAnnotation(value = "hello") @MyAnonotation(value = "hi") public void method1 () {} }
类型注解:Java8之后,关于元注解@Target的参数类型ElementType枚举值多了两个:TYPE_PARAMETER,TYPE_USE
TYPE_PARAMETER:表示该注解能写在类型变量的声明语句中
TYPE_USE:表示该注解能写在使用类型的任何语句中
JDK中常见的元注解 定义 :用来修饰注解的注解
Retention
功能 :只能用来修饰一个注解的定义,用于指定该注解可以保留多长时间,@Retention包含一个RetentionPolicy类型的成员变量,使用@Retention时必须为该成员变量指定值
1 2 @Retention(RetentionPolicy.SOURCE)
可以指定的值有三种 :
RetentionPolicy.SOURCE:编译器使用后,直接丢弃这种策略的注释。通俗来讲,就是该注解只在源码生效,例如@Override注解,就只是在使用javac工具编译源码(源文件)时判断源码内子类是否重写方法
RetentionPolicy.CLASS:这是默认值,编译器将把注解记录在class 文件中。当运行Java 程序时,JVM不会保留注解。通俗来讲,使用java工具来加载class文件和使用javac工具编译源码(源文件)时该注解生效
RetentionPolicy.RUNTIME:编译器将把注解记录在class 文件中.当运行Java 程序时,JVM会保留注解。程序可以通过反射获取该注释。通俗来讲,用java工具来加载class文件、使用javac工具编译源码(源文件)和运行Java程序时该注解生效
Target 功能 :用来修饰注解定义,用于指定被修饰的直接能用于修饰那些程序元素。@Target也包含一个名为value的成员变量,类型为字符串数组,故而可以接收多个
1 @Target(value={ElementType.METHOD})
Document 功能 :用于指定被该元注解修饰的注解将被javadoc工具提取成文档,即在生成文档时,可以看到该注解
1 2 3 4 5 @Documented @Retention(RetentionPolicy.RUNTIME) @Target(value={CONSTRUCTOR, FIELD, LOCAL_VARIABLE, METHOD, PACKAGE, PARAMETER, TYPE}) public @interface Deprecated {}
Inherited 功能:被它修饰的注解将具有继承性,如果某个类使用了被该元注解修饰的注解,则其子类将自动具有该注解
异常
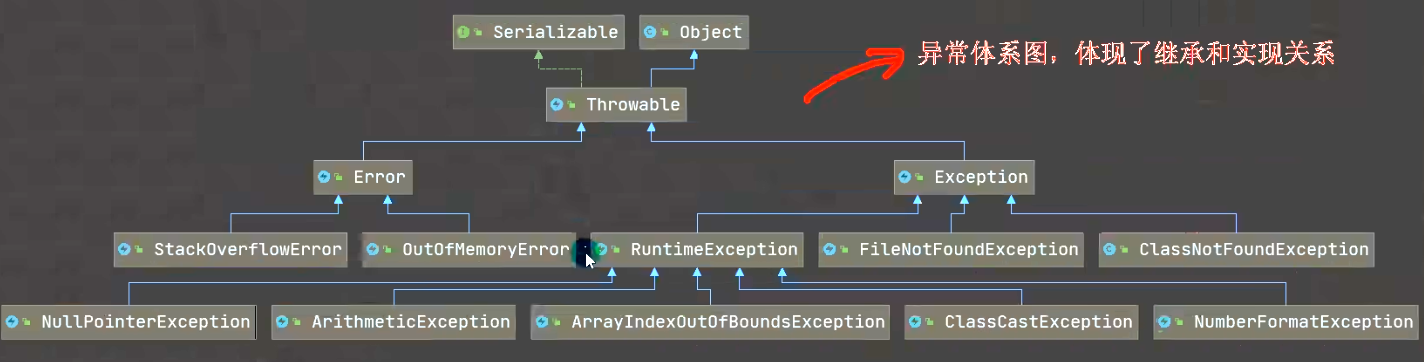
定义 :在Java程序运行过程中出现的不正常情况称为异常(开发过程中的语法错误和逻辑错误不是异常)分类 :
Error:Java虚拟机无法解决的严重问题,Error是严重错误,系统会崩溃。如:JVM系统内部异常,资源耗尽异常等等。
Exception:其他因编程错误或偶然的外在因素导致的一般性问题,可以使用针对性的代码进行处理。如:空指针访问,试图读取不存在的文件,网络连接中断等等。Exception又分为两大类:运行时异常(程序运行过程中出现的异常)和编译时异常(编译时,编译器检查出的异常)
异常体系图
常见的运行时异常
NullPointerException:空指针异常,当程序试图在需要对象的地方使用 null 时,抛出该异常
ArithmeticException:数学运算异常,当出现异常的运算条件时,抛出该异常
ArrayIndexOutOfBoundsException:数组下标越界异常,用非法索引访问数组时抛出的异常,当索引为负数或者大于等于数组大小,则该索引为非法索引
ClassCastException:类型转换异常,当试图将对象强制转换为不是该实例对象的子类时,会抛出该异常
NumberFormatException:数字格式不正确异常,当程序试图将字符串转换成一种数值类型,但该字符串不能转换为适当格式时,抛出该异常。使用该异常可以确保输入的是满足条件的数字
异常处理方式 定义 :当异常发生时,对异常的处理
try-catch-finally和throws二选一
try-catch-finally 处理机制
功能 :用于处理可能出现异常的代码,防止程序中断
1 2 3 4 5 6 7 8 9 10 try { } catch (Exception e) { } finally { }
细节 :
如果异常发生了,则try代码块中出现异常的代码后面的代码都不会运行,直接进入catch代码块
如果未发生异常,则顺序执行try代码块中的代码,不会执行catch代码块中的代码
无论是否发生异常,finally代码块的代码都会执行
如果有多个异常,可以使用多个catch块分别处理各个异常,但是要求处理子类异常catch代码块必须写在父类异常之前
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class Test { public static void main (String[] args) { try { int n1 = 1 / 0 ; String str = null ; System.out.println(str.length()); } catch (NullPointerException e) { System.out.println("空指针异常:" + e.getMessage()); } catch (ArithmeticException e) { System.out.println("算法运算异常:" + e.getMessage()); } catch (Exception e) { System.out.println(e.getMessage()); } finally { } } }
可以直接使用try-finally,但是这种用法相当于没有捕获异常,因此出现异常,程序会直接崩溃
throws 处理机制
功能 :当方法中可能出异常的代码没有用try-catch-finally处理时,该方法会通过throws抛出该异常给调用该方法的地方,依次抛出,直到抛出到JVM。JVM处理异常的方式:直接输出异常信息后退出程序
1 2 3 public class Test { public void f1 () throws 异常列表 {} }
如果没有显式处理异常,则默认采用throws处理机制
异常列表中一般是方法可能抛出的异常类或者它的父类
细节 :
对于编译时异常,必须通过try-catch或者throws进行处理
对于运行时异常,如果不进行处理,默认使用throws进行处理
子类重写父类时,对抛出异常的规定:子类重写的方法,所抛出的异常类型要么和父类抛出的异常一致,要么为父类抛出的异常类型的子类型
1 2 3 4 5 6 class Father { public void method () throws RuntimeException{} } class Son extends Father { public void method () throws NullPointerException{} }
try-catch和throws两种处理机制二选一即可
自定义异常 步骤 :
自定义异常类名,并继承Exception或者RuntimeException
如果是继承了Exception,属于编译时异常
如果是继承了RuntimeException,属于运行时异常
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class Test { public static void main (String[] args) { int age = 180 ; if (!(age >= 18 && age <= 120 )) { throw new AgeException ("输入的年龄应处于18到120之间" ); } System.out.println("你输入的年龄范围正确" ); } } class AgeException extends RuntimeException { public AgeException (String message) { super (message); } }
throw 和 throws的区别
****
意义 位置 后面跟的语法
throws 异常处理的一种方式
方法声明处
异常类型
throw 手动生成异常对象的关键字
方法体中
异常对象
常用类 包装类 定义 :针对八种基本数据类型设计的引用类型
基本数据类型 包装类
boolean
Boolean
char
Character
byte
Byte
short
Short
int
Integer
long
Long
float
Float
double
Double
上图中后六种包装类都继承了Number类
拆箱与装箱 定义 :将基本数据类型转换成包装类型就称之为装箱,将包装类转换为基本数据类型称之为拆箱
JDK5之前都是手动装箱和手动拆箱,JDK5后都是自动装箱和自动拆箱
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class Test { public static void main (String[] args) { int n1 = 100 ; Integer integer = new Integer (n1); Integer integer1 = Integer.valueOf(n1); int n2 = integer.intValue(); Integer integer2 = n2; int n3 = integer2; } }
其他包装类的拆箱装箱代码同理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class Wrapper03 { public static void main (String[] args) { Integer integer1 = new Integer (1 ); Integer integer2 = new Integer (1 ); System.out.println(integer1 == integer2); Integer integer3 = 1 ; Integer integer4 = 1 ; System.out.println(integer3 == integer4); Integer integer5 = 128 ; Integer integer6 = 128 ; System.out.println(integer5 == integer6); } }
包装类与String类的相互转换 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public class Wrapper02 { public static void main (String[] args) { Integer n = 100 ; String str = n + "" ; String str1 = String.valueOf(n); String str2 = n.toString(); String str3 = "123" ; Integer integer = new Integer (str3); Integer integer1 = Integer.parseInt(str3); System.out.println("ok~~~" ); } }
其他包装类同String类的转换同理
String 类
定义 :String 对象用于保存字符串,也就是一组字符序列,字符串常量对象是用双引号括起来的字符序列。字符串的字符使用Unicode字符编码,一个字符(无论是字母还是汉字)占两个字节
1 2 3 4 5 String s1 = new String ();String s2 = new String (String original);String s3 = new String (char [] a);String s4 = new String (char [] a, int startIndex, int count);
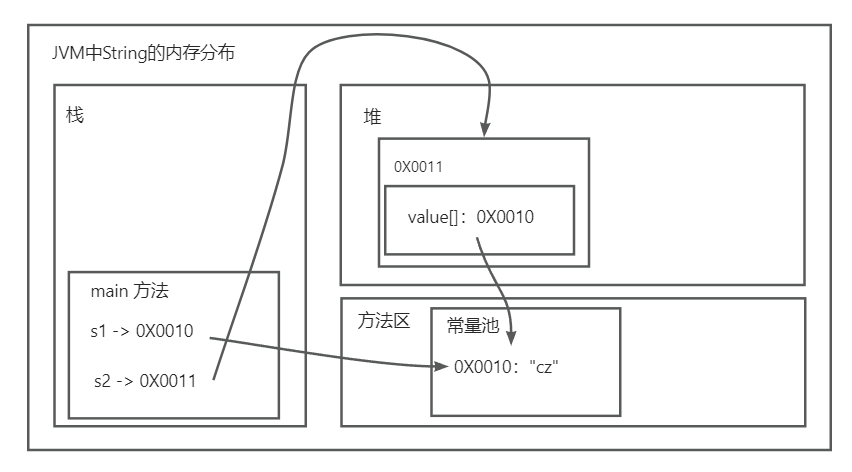
字符串常量赋值和new 创建String对象的区别 :
1 2 3 4 String s1 = "cz" ;String s2 = new String ("cz" );
方式一:先从常量池查看是否有”cz”存在,如果有,则直接指向,如果没有则重新创建,然后指向。s1最终指向的是常量池中的空间地址
方式二:先在堆中创建空间,里面维护了value属性,如果常量池中没有”cz”,则重新创建,如果有,则指向常量池的”cz”的地址。
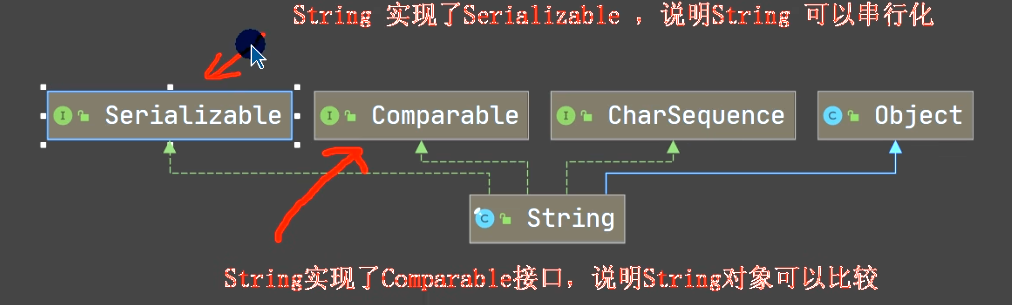
String 的继承类和实现接口 :
串行化表示该类型可以再网络上进行传输
细节 :
String 类是一个final类,不能被其他类继承
String 类有属性 private final char value[]; 用于存放字符串内容,该属性是一个final属性,故而它的**地址 **是不可修改的
1 2 3 4 5 6 7 8 public class Test { public static void main (String[] args) { final char [] value = {'t' ,'o' ,'m' }; value[2 ] = 'h' ; char [] v2 = {'t' ,'o' ,'h' }; } }
字符串常量 + 字符串常量 赋值给一个字符串变量 和 字符串变量 + 字符串变量 赋值给一个字符串变量的区别:
第一种赋值方式的字符串变量会直接指向两个常量的组合在常量池中的地址
第二种赋值方式的字符串变量会指向新创建的字符串对象在堆中的地址,而该对象中的value数组则会指向两个字符串变量的value数组指向的字符串常量的组合在常量池中的地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class Test { public static void main (String[] args) { String a = "123" ; String b = "456" ; String c = a + b; String d = "123" + "456" ; System.out.println(c == d); } }
总结:字符串常量相加,则该变量指向常量池。字符串变量相加,则该变量指向字符串对象在堆中的地址
String 常用方法 :
equals:区分大小写,判断内容是否相等
equalsIgnoreCase:忽略大小写,判断内容是否相等
length:获取字符的个数,字符串的长度
indexOf:获取字符在字符串中第一次出现的索引,索引从0开始,如果找不到,则返回-1
lastIndexOf:获取字符在字符串中最后一次出现的索引,索引从0开始,如果找不到,则返回-1
1 2 3 4 5 6 7 8 9 10 11 12 13 public class Test { public static void main (String[] args) { String a = "we@we@" ; System.out.println(a.indexOf('@' )); System.out.println(a.indexOf("we" )); System.out.println(a.lastIndexOf('@' )); System.out.println(a.lastIndexOf("we" )); } }
1 2 3 4 5 6 7 8 9 10 11 public class Test { public static void main (String[] args) { String a = "hello,world" ; System.out.println(a.substring(6 )); System.out.println(a.substring(0 , 5 )); System.out.println(a.substring(2 , 5 )); } }
trim:取出前后空格
charAt:获取某索引处的字符,注意不能使用 字符串名[下标] 的方式去获取
matches(String regStr):根据正则表达式进行匹配,返回boolean类型
replaceAll(String regStr, String repalcement):根据正则表达式进行匹配,然后使用replacement的内容替换匹配到的所有子字符串
toUpperCase:将字符串全部转为大写字母
toLowerCase:将字符串全部转为小写字母
concat:拼接字符串,返回字符串
1 2 3 4 5 6 7 8 public class Test { public static void main (String[] args) { String str = "hello" ; String newStr = str.concat(",world" ).concat(",你好" ).concat(",世界" ); System.out.println(str); System.out.println(newStr); } }
repalce:替换字符串中的某些字符串,返回字符串
1 2 3 4 5 6 7 8 public class Test { public static void main (String[] args) { String str = "ab,b,ab,b" ; String newStr = str.replace("ab" , "b" ); System.out.println(str); System.out.println(newStr); } }
split:根据字符串分隔字符串,返回字符串数组,可能需要用到转义字符,支持根据正则表达式进行分隔
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class Test { public static void main (String[] args) { String a = "hello,world,你好,世界" ; String[] splits = a.split("," ); for (String split : splits) { System.out.println(split); } String str = "E:\\temp\\input.txt" ; splits = str.split("\\\\" ); for (String split : splits) { System.out.println(split); } } }
compareTo:依次对比两个字符串的每个字符,如果有字符不同,则返回第一个字符串中的字符 - 第二个字符串中的字符的值,如果前面字符都相同,则返回第一个字符串的长度 - 第二个字符串的长度
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public class Test { public static void main (String[] args) { String str1 = "jack" ; String str2 = "jackjack" ; System.out.println(str1.compareTo(str2)); } }
toCharArray:将字符串转换为字符数组
format:格式化字符串,%s 字符串,%c 字符,%d 整型,%.2f 浮点型
1 2 3 4 5 6 7 8 9 public class Test { public static void main (String[] args) { String name = "张三" ; String gender = "男" ; int age = 18 ; String str = String.format("姓名:%s,性别:%s,年龄:%d" , name, gender, age); System.out.println(str); } }
StringBuffer 类
定义 :StringBuffer 代表可变的字符序列,可以对字符串内容进行增删。很多方法和String相同,但是StringBuffer是可变长度的。StringBuffer 和 String 的区别 :
String 的底层是 private final char[] value 属性去指向常量池中的字符串常量(字符数组),当要修改该String类型的对象的字符串内容时,会在常量池中创建一个字符串常量,然后value属性去指向该字符串常量。这就导致了String对象每次更新内容都要修改value指向的地址,进而效率低下
StringBuffer 的底层是 private char[] value 属性指向堆中的字符串变量(字符数组),当要修改该StringBuffer类型的对象的字符串内容时,可以直接操作该字符数组,不用更换地址。只有当该字符数组的大小(默认是16)不够用时,才会进行扩容处理,此时才会更新地址,进而效率比较高
StringBuffer 常用构造器 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class Test { public static void main (String[] args) { StringBuffer sb1 = new StringBuffer (); StringBuffer sb2 = new StringBuffer (100 ); StringBuffer sb3 = new StringBuffer ("String" ); } }
String 和 StringBuffer 的相互转换 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class Test { public static void main (String[] args) { String str = "hello String" ; StringBuffer stringBuffer1 = new StringBuffer (str); StringBuffer stringBuffer2 = new StringBuffer (); stringBuffer2 = stringBuffer2.append(str); StringBuffer stringBuffer3 = new StringBuffer ("com.itcz" ); String s = stringBuffer3.toString(); String s1 = new String (stringBuffer3); } }
StringBuffer 的常用方法 :
append:添加字符串
delete(start, end):删除字符串中索引从start开始,end结束(不包括end)的字符串
replace(start, end, String):将字符串中索引从start开始,end结束(不包括end)的字符串替换为第三个参数的内容
indexOf:查找子串在字符串第一次出现的索引,如果找不到返回-1
insert(index, String):在字符串的索引为index的位置插入第二个参数的内容,原来索引为index字符后面的所有字符(包括index索引所在的字符)全部自动后移
length:获取字符串的长度
细节 :
StringBuffer 的直接父类是 AbstractStringBuilder,该类中有属性char[] value,不是final类型,故而存储在堆中,并且value属性是用来存放字符串内容的
StringBuffer 是一个 final 类,不能被继承,它还实现了 Serializable 接口,即StringBuffer的对象可以串行化,即可以保存在文件中,还可以在网络中传输
StringBuilder 类
定义 :一个可变的字符序列。此类提供一个与StringBuffer兼容的API,但不保证同步(StringBuilder 不是线程安全)。该类被设计用作StringBuffer的一个简易替换,用在字符串缓冲区被单个线程使用的时候。如果可能,建议优先采用该类,因为在大多数实现中,它比StringBuffer要快。String 、StringBuffer 和 StringBuilder 的区别 :
StringBuffer 和 StringBuilder 非常类似,均代表可变的字符序列,而且方法也是一样
String 则是不可变字符序列,效率低,但是复用率高
StringBuffer 是可变字符序列,效率高(增删)、线程安全
StringBulider 是可变字符序列,效率最高,但是线程不安全
String类型的对象进行大量 += 字符串的操作,会导致大量副本字符串对象留在内存中,降低效率。总结:如果要对字符串进行大量修改,不要使用String类型
细节 :
StringBuilder 的直接父类是 AbstractStringBuilder,并且实现了Serializable接口,故该类的对象可以串行化
StringBuilder 是final类,不能被继承,并且该对象字符序列仍然是存放在其父类的value属性中,因此字符序列存放在堆中
StringBuilder 的所有方法都没有做同步互斥处理,因此推荐在单线程的情况下使用StringBuilder
Math 工具类
定义 :专用于操作数字的final类,提供了大量的静态方法常用方法 :
abs:求参数的绝对值
pow:求第一个参数的第二个参数的次方
ceil:向上取整,返回double类型
floor:向下取整,返回double类型
round:四舍五入,返回double类型
sqrt:求开方
random:返回一个大于等于0,小于1的随机小数
获取一个a -b 之间(包括a和b)的一个随机整数的公式:
Math.floor(Math.random() * (b - a + 1) )
max:求两个数的最大值
min:求两个数的最小值
Arrays 工具类
定义 :该类是专用于操作和管理数组的final类,内部定义了一系列静态方法常用方法 :
toString(数组类型的对象):返回数组的字符串形式
sort:对数组进行排序
该方法可分为两种,默认排序和定制排序。
sort(数组类型的对象):默认从小到大对数组进行排序
sort(数组类型的对象,实现Comparator接口的对象):通过实现Comparator接口中的compare方法,影响数组排序的排序规则(是从小到大还是从大到小),其底层排序算法用的二分排序树
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 import java.util.Arrays;import java.util.Comparator;public class Test { public static void main (String[] args) { Book[] books = new Book [4 ]; books[0 ] = new Book ("红楼梦" , 100 ); books[1 ] = new Book ("金瓶梅" , 90 ); books[2 ] = new Book ("青年文摘" , 5 ); books[3 ] = new Book ("Java从入门到放弃" , 300 ); bubble(books, new Comparator <Object>() { @Override public int compare (Object o1, Object o2) { Book b1 = (Book) o1; Book b2 = (Book) o2; if (b1.getPrice() - b2.getPrice() > 0 ) { return 1 ; } else if (b1.getPrice() - b2.getPrice() == 0 ) { return 0 ; } else { return -1 ; } } }); System.out.println(Arrays.toString(books)); } public static void bubble (Object[] arr, Comparator<Object> comparable) { for (int i = 0 ; i < arr.length; i++) { for (int j = 0 ; j < arr.length - 1 - i; j++) { if (comparable.compare(arr[j], arr[j + 1 ]) > 0 ) { Object temp = arr[j]; arr[j] = arr[j + 1 ]; arr[j + 1 ] = temp; } } } } } class Book { private String name; private double price; public Book (String name, double price) { this .name = name; this .price = price; } public String getName () { return name; } public void setName (String name) { this .name = name; } public double getPrice () { return price; } public void setPrice (double price) { this .price = price; } @Override public String toString () { return "Book{" + "name='" + name + '\'' + ", price=" + price + '}' ; } }
binarySearch(数组类型的对象, 值):要求数组必须是升序的,通过二分查找法查找该值在数组的下标
copyOf(数组类型的对象, 拷贝的个数):拷贝数组,返回一个新数组
fill(数组类型的对象, 元素值):将数组中所有元素都改为第二个参数值
equals(数组类型的对象,数组类型的对象):对比两个数组的每个位置元素是否一样,不一样返回false,反之返回true
asList(数组类型的对象):会将数组中的所有数据转成一个List集合
System 工具类
定义 :和系统指令相关的final类,内部有一系列的静态方法常用方法 :
exit:退出当前程序
arraycopy(src, srcPos, dest, destPos, length):复制数组元素,比较适合底层调用,Arrays.copyOf方法底层就是调用的System.arraycopy方法。参数说明:
src:原数组
srcPos:从原数组的哪个位置开始拷贝
dest:目标数组
destPos:拷贝的元素从目标的数组的哪个索引开始赋值
length:拷贝的数据个数
currentTimeMillens:返回当前时间距离1970-1-1的毫秒数
gc:运行垃圾回收器
BigInteger 类
定义 :用来处理和存储非常大的整数的final类
1 2 3 4 5 6 7 8 9 10 import java.math.BigInteger;public class BigInteger01 { public static void main (String[] args) { BigInteger bigInteger1 = new BigInteger ("123456789123456789" ); BigInteger bigInteger2 = new BigInteger ("10" ); BigInteger bigInteger = bigInteger1.add(bigInteger2); System.out.println(bigInteger); } }
常用方法 :
add:加法
substrct:减法
multiply:乘法
divide:除法
BigDecimal 类
定义 :用来处理和存储非常大的小数的final类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import java.math.BigDecimal;import java.math.RoundingMode;public class BigDecimal01 { public static void main (String[] args) { BigDecimal bigDecimal1 = new BigDecimal ("123.123123456456" ); BigDecimal bigDecimal2 = new BigDecimal ("1.2" ); System.out.println(bigDecimal1.add(bigDecimal2)); System.out.println(bigDecimal1.subtract(bigDecimal2)); System.out.println(bigDecimal1.multiply(bigDecimal2)); System.out.println(bigDecimal1.divide(bigDecimal2, RoundingMode.CEILING)); } }
常用方法 :
add:加法
substrct:减法
multiply:乘法
divide:除法
日期类 Date 类
定义 :第一代日期类,可以用来表示时间,精确到毫秒
1 2 3 4 Date date1 = new Date ();Date date2 = new Date (9867 );
SimpleDateFormat 类 :格式和解析日期的类
format:格式化时间输出形式,返回字符串类型
parse:解析时间,得到Date对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import java.text.ParseException;import java.text.SimpleDateFormat;import java.util.Date;public class Test { public static void main (String[] args) throws ParseException { Date date1 = new Date (); Date date2 = new Date (9867 ); System.out.println("date2 = " + date2); SimpleDateFormat sdf = new SimpleDateFormat ("yyyy年MM月dd日 HH:mm:ss E" ); String format = sdf.format(date1); System.out.println(format); Date date = sdf.parse(format); System.out.println(date); } }
Calendar 类
定义 :第二代日期类,可以用来表示时间,精确到毫秒常用方法 :
getInstance:静态方法,该类的构造器是私有的,只能通过该方法得到Calendar的对象
get(Calendar的某个字段):获取该对象的某个日历字符
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import java.util.Calendar;public class Calender01 { public static void main (String[] args) { Calendar calendar = Calendar.getInstance(); System.out.println(calendar); System.out.println("年:" + calendar.get(Calendar.YEAR)); System.out.println("月:" + calendar.get(Calendar.MONTH) + 1 ); System.out.println("日:" + calendar.get(Calendar.DAY_OF_MONTH)); System.out.println("小时:" + calendar.get(Calendar.HOUR)); System.out.println("分钟:" + calendar.get(Calendar.MINUTE)); System.out.println("秒:" + calendar.get(Calendar.SECOND)); System.out.println(calendar.get(Calendar.YEAR) + "年" + (calendar.get(Calendar.MONTH) + 1 ) + "月" + calendar.get(Calendar.DAY_OF_MONTH) + "日" ); } }
LocalDateTime 类
定义 :第二代日期类,可以用来表示时间,精确到毫秒
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import java.time.LocalDate;import java.time.LocalDateTime;import java.time.LocalTime;public class LocalDateTime01 { public static void main (String[] args) { LocalDateTime ldt = LocalDateTime.now(); LocalDate ld = LocalDate.now(); LocalTime lt = LocalTime.now(); System.out.println("年=" + ldt.getYear()); System.out.println("年=" + ld.getYear()); System.out.println("月=" + ldt.getMonth()); System.out.println("月=" + ld.getMonth()); System.out.println("月=" + ldt.getMonthValue()); System.out.println("月=" + ld.getMonthValue()); System.out.println("日=" + ld.getDayOfMonth()); System.out.println("日=" + ld.getDayOfMonth()); System.out.println("时=" + ldt.getHour()); System.out.println("时=" + lt.getHour()); System.out.println("分=" + ldt.getMinute()); System.out.println("分=" + lt.getMinute()); System.out.println("秒=" + ldt.getSecond()); System.out.println("秒=" + lt.getSecond()); } }
DateTimeFormatter 类 :用于格式化LocalDateTime对象的时间输出格式
ofPattern(字符串):静态方法,通过字符串创建格式化对象
format:对日期对象进行格式化,返回字符串
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import java.time.LocalDate;import java.time.LocalDateTime;import java.time.LocalTime;import java.time.format.DateTimeFormatter;public class LocalDateTime01 { public static void main (String[] args) { LocalDateTime ldt = LocalDateTime.now(); LocalDate ld = LocalDate.now(); LocalTime lt = LocalTime.now(); DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy年MM月dd日 HH:mm:ss E" ); String format = dateTimeFormatter.format(ldt); System.out.println(format); } }
Instant 类:时间戳类,提供了一系列和Date类转换的方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import java.util.Date;import java.time.Instant;public class Instant01 { public static void main (String[] args) { Instant instant = Instant.now(); System.out.println(instant); Date date = Date.from(instant); Instant instant1 = date.toInstant(); } }
main 方法
JVM调用main方法,所以该方法的访问权限必须是public
JVM调用main方法时,不需要创建对象,故而该方法必须是static修饰的静态方法
该方法接收String类型的数组参数,该数组中保存直线Java命令时传递给所运行的类的参数
命令执行:java 执行的程序 参数1 参数2 参数3
main方法可以直接访问本类的静态成员
集合 集合的框架体系 集合分为两种:单列集合和双列集合
Collection
基本介绍 :
Collection 实现子类可以存放多个元素,每个元素可以是Object
有些Collection的实现类,可以存放重复的元素,有些不可以
有些Collection的实现类,有些是有序的(List),有些不是有序(Set)
Collection接口没有直接的实现子类,是通过它的子接口Set和List来实现的
常用方法 :
add:添加单个元素
remove:删除指定元素
remove(int index):通过下标索引删除集合中的元素,返回删除的Obejct对象
remove(Object):删除集合中的指定元素,返回boolean类型
contains:查找元素是否存在
size:获取元素个数
isEmpty:判断是否为空
clear:清空元素
addAll(Collection C):添加多个元素
containsAll(Collection C):查找多个元素是否都存在
removeAll(Collection C):删除多个元素
使用迭代器遍历Collection中的元素
基本介绍 :
Iterator 对象称为迭代器,主要用于遍历 Collection 集合中的元素
所有实现了Collection接口的集合类都有一个iterator()方法,用以返回一个实现了Iterator接口的对象,即返回一个迭代器
Iterator 仅用于遍历集合,Iterator 本身不存放对象
Iterator 接口中常用方法 :
hasNext():用于判断当前迭代器指针指向的下一个元素是否存在,存在返回true,不存在返回false
next():用于将当前迭代器指针先下移,后返回当前迭代器指针指向的元素
迭代器底层原理 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 import java.util.*;import java.util.function.Consumer;public class Test { @SuppressWarnings({"all"}) public static void main (String[] args) { Collection list = new ArrayList (); list.add("java" ); list.add("php" ); list.add("python" ); list.add("jack" ); Iterator iterator = list.iterator(); while (iterator.hasNext()) { Object next = iterator.next(); System.out.println("object=" + next); } } }
使用迭代器遍历的语法 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 import java.util.ArrayList;import java.util.Collection;import java.util.Iterator;public class List01 { @SuppressWarnings({"all"}) public static void main (String[] args) { Collection list = new ArrayList (); list.add(new Person ("zhangsan" , 18 , "男" )); list.add(new Person ("lisi" , 18 , "男" )); list.add(new Person ("wangwu" , 18 , "男" )); list.add(new Person ("zhaoliu" , 18 , "男" )); list.add("jack" ); Iterator iterator = list.iterator(); while (iterator.hasNext()) { Object next = iterator.next(); System.out.println("object=" + next); } iterator = list.iterator(); while (iterator.hasNext()) { Object next = iterator.next(); System.out.println("object=" + next); } } } class Person { private String name; private int age; private String gender; public Person (String name, int age, String gender) { this .name = name; this .age = age; this .gender = gender; } public String getName () { return name; } public void setName (String name) { this .name = name; } public int getAge () { return age; } public void setAge (int age) { this .age = age; } public String getGender () { return gender; } public void setGender (String gender) { this .gender = gender; } @Override public String toString () { return "Person{" + "name='" + name + '\'' + ", age=" + age + ", gender='" + gender + '\'' + '}' ; } }
增强for循环遍历Collection中的元素 增强for的底层还是用得迭代器进行遍历,只是语法上比较简单
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 package com.itcz;import java.util.ArrayList;import java.util.Collection;import java.util.Iterator;public class List02 { @SuppressWarnings({"all"}) public static void main (String[] args) { Collection list = new ArrayList (); list.add(new Person1 ("zhangsan" , 18 , "男" )); list.add(new Person1 ("lisi" , 18 , "男" )); list.add(new Person1 ("wangwu" , 18 , "男" )); list.add(new Person1 ("zhaoliu" , 18 , "男" )); list.add("jack" ); for (Object o : list) { System.out.println("object=" + o); } } } class Person1 { private String name; private int age; private String gender; public Person1 (String name, int age, String gender) { this .name = name; this .age = age; this .gender = gender; } public String getName () { return name; } public void setName (String name) { this .name = name; } public int getAge () { return age; } public void setAge (int age) { this .age = age; } public String getGender () { return gender; } public void setGender (String gender) { this .gender = gender; } @Override public String toString () { return "Person{" + "name='" + name + '\'' + ", age=" + age + ", gender='" + gender + '\'' + '}' ; } }
利用Lambda表达式遍历Collection中的元素 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import java.util.ArrayList;import java.util.List;import java.util.function.Consumer;public class List10 { @SuppressWarnings({"all"}) public static void main (String[] args) { List list = new ArrayList (); list.add("String" ); list.add("java" ); list.add(1 ); list.forEach(new Consumer () { @Override public void accept (Object o) { System.out.println(o); } }); System.out.println("=====使用Lambda表达式遍历集合元素=======" ); list.forEach(o -> System.out.println(o)); } }
List 接口
基本介绍 :
List接口是Collection接口的实现类(子接口)
List集合中的元素有序(即添加顺序和取出顺序一致)、且可重复
List有序,故而支持索引
常用的实现类有:ArrayList、LinkedList、Vector
常用方法 :
void add(int index, Object ele):在index位置插入ele元素,原来index位置之后的元素(包括index所在的元素)依次后移
boolean addAll(int index, Collection eles):从index位置开始将eles中的所有元素添加进来,原来index位置之后的元素(包括index所在的元素)依次后移
Object get(int index):获取指定index位置的元素
int indexOf(Object obj):返回obj在集合中首次出现的位置
int lastIndexOf(Object obj):返回obj在当前集合中最后出现的位置
Object remove(int index):一移除指定index位置的元素,并返回此元素
Object set(int index, Object ele):设置指定index位置的元素为ele,相当于替换
List subList(int fromIndex, int toIndex):返回从fromIndex到toIndex位置的子集合,左闭右开
还拥有Collection接口的所有方法,因为List接口是Collection接口的子接口
细节 :
ArrayList 可以加入空对象:null
ArrayList 是由数组来实现数据存储的
ArrayList 基本等同于 Vector,但是 ArrayList 是线程不安全的,执行效率比较高
ArrayList 底层结构和源码分析
底层结构和扩容机制 :
ArrayList中维护了一个Object类型的数据elmentData。transient Object[] elementData; 其中transient修饰的属性不会被序列化
当创建ArrayList对象时,如果使用的是无参构造器,则初始化elementData容量为0,第一次添加元素,则扩容elementData为10,如需再次扩容,则扩容elementData为原来的1.5倍
如果使用的是指定大小的构造器,则初始elementData容量为指定大小,如果需要扩容,则直接扩容elementData为原来的1.5倍
当一次添加多个元素,并且添加后的总元素个数大于之前数组的长度的1.5倍,此时扩容后的数组大小为添加后的总元素个数
无参构造器创建的ArrayList进行扩容的底层源码剖析 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 import java.util.ArrayList;import java.util.List;public class List05 { @SuppressWarnings({"all"}) public static void main (String[] args) { List list = new ArrayList (); for (int i = 0 ; i < 10 ; i++) { list.add(i); } for (int i = 10 ; i < 15 ; i++) { list.add(i); } list.add(100 ); list.add(200 ); list.add(300 ); } }
有参构造器创建的ArrayList进行扩容的底层源码剖析 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 import java.util.ArrayList;import java.util.List;public class List06 { @SuppressWarnings({"all"}) public static void main (String[] args) { List list = new ArrayList (8 ); for (int i = 0 ; i < 10 ; i++) { list.add(i); } for (int i = 10 ; i < 15 ; i++) { list.add(i); } list.add(100 ); list.add(200 ); list.add(300 ); } }
一次添加多个元素,并且添加后的总元素个数大于之前数组的长度的1.5倍的底层源码剖析 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 import java.util.ArrayList;import java.util.List;public class List11 { @SuppressWarnings({"all"}) public static void main (String[] args) { List list1 = new ArrayList (); List list2 = new ArrayList (); for (int i = 0 ; i < 20 ; i++) { list2.add(i); } list1.add(0 ); list1.addAll(list2); } }
Vector 底层结构和源码分析
基本介绍 :
Vector 底层也是用的一个对象数组存储数据,protected Object[] elementData;
Vector 是线程同步的,即线程安全的,Vector类的操作方法带有synchronized关键字,如果开发中涉及线程安全,推荐使用Vector
扩容机制 :
当创建Vector对象时,如果使用的是无参构造器,则初始化elementData容量为10,如需扩容,则扩容elementData为原来的2倍
如果使用的是指定大小的构造器,则初始elementData容量为指定大小,如果需要扩容,则直接扩容elementData为原来的2倍
还可以通过构造器指定每次扩容大小
无参构造器创建的Vector进行扩容的底层源码剖析 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 import java.util.List;import java.util.Vector;public class List07 { @SuppressWarnings({"all"}) public static void main (String[] args) { List list = new Vector (); for (int i = 1 ; i <= 10 ; i++) { list.add(i); } list.add(100 ); } }
有参构造器创建的Vector进行扩容的底层源码剖析 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 package com.itcz;import java.util.List;import java.util.Vector;public class List08 { @SuppressWarnings({"all"}) public static void main (String[] args) { List list = new Vector (10 , 5 ); for (int i = 1 ; i <= 10 ; i++) { list.add(i); } list.add(100 ); } }
LinkedList 底层结构和源码分析
底层结构 :
LinkedList底层存储数据使用的是双向链表,故而不需要进行扩容处理
LinkedList也是线程不安全的集合
LinkedList 查询数据慢,增删数据块,同时操作首尾元素速度也是极快的
常用方法 :
特有方法 说明
public void addFirst(E e)
在该列表开头插入指定元素
public void addLast(E e)
将指定元素追加到此列表的末尾
public E getFirst()
返回该列表中的第一个元素
public E getLast()
返回该列表中的最后一个元素
public E removeFirst()
从此列表中删除并返回第一个元素
public E removeLast()
从此列表中删除并返回最后一个元素
常用方法的源码分析 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 import java.util.Iterator;import java.util.LinkedList;public class List09 { @SuppressWarnings({"all"}) public static void main (String[] args) { LinkedList linkedList = new LinkedList (); System.out.println("添加数据" ); linkedList.add(1 ); linkedList.add(2 ); linkedList.add(3 ); System.out.println("list=" + linkedList); System.out.println("删除集合中的第一个元素" ); linkedList.remove(); System.out.println("list=" + linkedList); System.out.println("修改集合中的指定元素" ); linkedList.set(1 , 999 ); System.out.println("list=" + linkedList); System.out.println("====使用增强for遍历集合====" ); for (Object o : linkedList) { System.out.println(o); } System.out.println("====使用普通for遍历集合=====" ); for (int i = 0 ; i < linkedList.size(); i++) { System.out.println(linkedList.get(i)); } System.out.println("====使用迭代器遍历集合====" ); Iterator iterator = linkedList.iterator(); while (iterator.hasNext()) { Object next = iterator.next(); System.out.println(next); } } }
ArrayList 和 LinkedList 比较
****
底层结构 增删的效率 改查的效率
ArrayList
可变数组
较低,数组扩容
较高
LinkedList
双向链表
较高,通过链表追加
较低
如果改查的操作多,选择ArrayList
如果增删的操作多,选择LinkedList
Set 接口
基本介绍 :
Set 集合中的元素是无序的(添加和取出的顺序不一致),没有索引
不允许重复元素,所以最多包含一个null
但是取出的顺序是固定的,即只要数据存入了,那么它的位置不会发生改变
常用方法 :
remove(Objec obj):删除指定元素
add(Object obj):添加元素
还拥有Collection接口的所有方法,因为Set接口是Collection接口的子接口
遍历方式 :
不能通过索引进行遍历,因为Set接口不提供get方法
HashSet
基本介绍 :
HashSet 类 实现了 Set 接口
HashSet 底层实际上是 HashMap,而HashMap的底层存储数据用的是数组 + 链表的存储结构(类似邻接表)
1 2 3 Public HashSet () { map = new hashMap <>(); }
底层数据结构 :
链表结点Node定义如下,它是HashMap的静态内部类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 static class Node <K,V> implements Map .Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) { this .hash = hash; this .key = key; this .value = value; this .next = next; } public final K getKey () { return key; } public final V getValue () { return value; } public final String toString () { return key + "=" + value; } public final int hashCode () { return Objects.hashCode(key) ^ Objects.hashCode(value); } public final V setValue (V newValue) { V oldValue = value; value = newValue; return oldValue; } public final boolean equals (Object o) { if (o == this ) return true ; if (o instanceof Map.Entry) { Map.Entry<?,?> e = (Map.Entry<?,?>)o; if (Objects.equals(key, e.getKey()) && Objects.equals(value, e.getValue())) return true ; } return false ; } }
数组table的定义如下,默认是null,它是HashMap的属性
1 transient Node<K,V>[] table;
存储数据时的扩容机制 :
添加元素时,如果table数组为null,则会进行第一次扩容,此时数组长度会扩容到16个,并设置数组阈值为12(16 * 0.75),如果不为null,会通过哈希算法得到一个hash值,再将数组table长度 - 1 与哈希值进行按位与运算得到索引
得到索引后会通过索引找到该索引在数组table中的位置,判断该数组位置上是否有元素
如果没有,则直接添加到数组中,如果有,则调用equals方法进行比较,如果相同就放弃添加,如果不同,则添加到链表最后
添加成功后会将存储元素总个数 + 1,并对比总个数 和 数组的阈值,超过了会对数组table进行扩容,扩容后的数组长度为原来的两倍,并将数组阈值设置为原来的两倍
如果旧数组不为null,则会将旧数组的元素按照下列规则拷贝到新数组中
如果旧数组元素为单个结点(即链表中只有一个结点),则按照hash值与新数组长度 - 1按位与得到该元素在新数组的索引值
如果就数组元素类型为红黑树,则按照红黑树的规则进行拆分红黑树
如果数组元素不为单个结点(即链表中不止一个结点),此时会通过计算链表中每个结点的hash值与旧数组的长度进行按位与运算的结果,判断该结果是否为0
为0,则将该元素添加到低位链表(新创建)的最后
不为0,则将该元素添加到高位链表(新创建)的最后
- 最后将低位链表添加到新数组[旧索引],高位链表添加到新数组[旧索引 + 旧数组长度]
在Java8中,插入元素后,如果一条链表的长度大于了TREEIFY_THRESHOLD(默认为8),并且数组table的大小大于等于了MIN_TREEIFY_CAPACITY(默认64),就会进行树化(红黑树)
添加元素时源码分析 :
HashSet类型的对象第一次添加数据的源码分析如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 import java.util.HashSet;public class Set02 { @SuppressWarnings({"all"}) public static void main (String[] args) { HashSet hashSet = new HashSet (); hashSet.add("java" ); hashSet.add("php" ); hashSet.add("java" ); System.out.println("set=" + hashSet); } }
HashSet类型的对象第二次添加数据的源码分析如下(索引未重复)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import java.util.HashSet;public class Set02 { @SuppressWarnings({"all"}) public static void main (String[] args) { hashSet.add("java" ); hashSet.add("php" ); hashSet.add("java" ); System.out.println("set=" + hashSet); } }
HashSet类型的对象添加相同元素的源码分析如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 import java.util.HashSet;public class Set02 { @SuppressWarnings({"all"}) public static void main (String[] args) { hashSet.add("java" ); hashSet.add("php" ); hashSet.add("java" ); System.out.println("set=" + hashSet); } }
HashSet存取顺序不一致的原因 :
因为遍历HashSet集合是通过依次遍历数组table实现的,先判断数组table中每个元素是否为null,如果为null,直接遍历下一个元素,不为null,则通过该元素依次遍历链表/红黑树,故而取出顺序和存入顺序不一致
HashSet中的元素没有索引的原因 :
因为HashSet中元素可能是在同一个链表中存储,此时它们在数组中的下标是一样,这就不能通过索引值找到某一个特定元素,故而HashSet取消了索引机制
HashSet利用什么机制保证数据去重的 :
底层通过hashCode方法和equals方法来对比存入的数据是否一致,如果一致则不会进行添加
使用迭代器遍历HashSet集合底层源码分析 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 import java.util.HashSet;import java.util.Iterator;public class Set07 { @SuppressWarnings({"all"}) public static void main (String[] args) { HashSet hashSet = new HashSet (); hashSet.add("java" ); hashSet.add("php" ); Iterator iterator = hashSet.iterator(); while (iterator.hasNext()) { Object next = iterator.next(); System.out.println(next); } } }
红黑树
红黑树的定义(红黑规则) :
每个结点要么为黑色,要么为红色
根结点必须为黑色
如果结点没有子结点或者父结点,则该结点对应的相应结点指针为Nil,这些Nil视为叶结点,每个叶结点(Nil)都是黑色的
如果某个结点是红色,那么它的子结点必须是黑色(不能出现两个红色结点相连的情况)
对于每个结点,从该结点到其所有后代叶结点的简单路径上均包含相同数目的黑色结点
理解即可,不需要死记硬背
添加结点后平衡规则 :(最开始添加结点的规则就是二叉查找树的添加规则)
注意:添加元素的结点默认为红色
理解即可,不需要死记硬背
LinkedhashSet
基本介绍 :
LinkedHashSet 是 HashSet 的子类
LinkedHashSet 底层是一个 LinkedHashMap 类型的对象,更底层是维护了一个数组 + 双向链表 + 单链表 + 红黑树的数据结构,LinkedHashMap 是 HashMap 的子类
LinkedHashSet 根据元素的 hashCode 值来决定元素的存储位置,同时使用链表维护元素的次序,这使得元素看起来是以插入顺序保存的
LinkedHashSet 不允许添加重复元素
底层结构 :
双向链表结点Entry定义如下,它是LinkedHashMap的静态内部类,并且继承了父类HashMap中的静态内部类Node,故而table表中可以存储双向链表的结点
1 2 3 4 5 6 static class Entry <K,V> extends HashMap .Node<K,V> { Entry<K,V> before, after; Entry(int hash, K key, V value, Node<K,V> next) { super (hash, key, value, next); } }
数组table的定义如下,默认是null,它是HashMap的属性
1 transient Node<K,V>[] table;
首尾指针定义如下,默认是null,它是LinkedHashMap的属性
1 2 3 4 5 6 transient LinkedHashMap.Entry<K,V> head;transient LinkedHashMap.Entry<K,V> tail;
存储数据时的扩容机制(无参构造方法创建的对象) :
无参构造方法会使底层数组阈值设为16(初始数组长度),加载因子设为0.75(可根据有参构造方法自定义初始数组长度和加载因子)
添加元素时,如果table数组为null,则会进行第一次扩容,此时数组长度会扩容到16个(初始数组长度),并设置数组阈值为12(16 * 0.75),如果不为null,会通过哈希算法得到一个hash值,再将数组table长度 - 1 与哈希值进行按位与运算得到索引
得到索引后会通过索引找到该索引在数组table中的位置,判断该数组位置上是否有元素
如果没有,则直接添加到数组table中并且添加到双向链表的最后,如果有,则调用equals方法进行比较,如果相同就放弃添加,如果不同,则添加到单链表(该索引所在的链表)的最后并添加到双向链表最后
添加成功后会将存储元素总个数 + 1,并对比总个数 和 数组的阈值,超过了会对数组table进行扩容,扩容后的数组长度为原来的两倍,并将数组阈值设置为原来的两倍
如果旧数组不为null,则会将旧数组的元素按照下列规则拷贝到新数组中
如果旧数组元素为单个结点(即单链表中只有一个结点),则按照hash值与新数组长度 - 1按位与得到该元素在新数组的索引值
如果就数组元素类型为红黑树,则按照红黑树的规则进行拆分红黑树
如果数组元素不为单个结点(即单链表中不止一个结点),此时会通过计算单链表中每个元素的hash值与旧数组的长度进行按位与运算的结果,判断该结果是否为0
为0,则将该元素添加到低位链表(新创建)的最后
不为0,则将该元素添加到高位链表(新创建)的最后
- 最后将低位链表添加到新数组[旧索引],高位链表添加到新数组[旧索引 + 旧数组长度]
在Java8中,插入元素后,如果一条链表的长度大于了TREEIFY_THRESHOLD(默认为8),并且数组table的大小大于等于了MIN_TREEIFY_CAPACITY(默认64),就会进行树化(红黑树)
添加元素时的底层源码分析 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 package com.itcz;import java.util.LinkedHashSet;public class Set05 { @SuppressWarnings({"all"}) public static void main (String[] args) { LinkedHashSet linkedHashSet = new LinkedHashSet (); linkedHashSet.add(456 ); linkedHashSet.add(456 ); linkedHashSet.add("Java" ); linkedHashSet.add(new Customer1 ("tom" , 1001 )); } } class Customer1 { private String name; private int no; public Customer1 (String name, int no) { this .name = name; this .no = no; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 package com.itcz;import java.util.LinkedHashSet;public class Set05 { @SuppressWarnings({"all"}) public static void main (String[] args) { LinkedHashSet linkedHashSet = new LinkedHashSet (); linkedHashSet.add(456 ); linkedHashSet.add(456 ); linkedHashSet.add("Java" ); linkedHashSet.add(new Customer1 ("tom" , 1001 )); } } class Customer1 { private String name; private int no; public Customer1 (String name, int no) { this .name = name; this .no = no; } }
LinkedHashSet集合存取数据顺序一致的原因 :
由于LinkedHashSet存储数据时会调用自己的newNode方法,该方法又会调用linkedNodeLast方法,此方法会将元素添加到双向链表的最后,并使尾指针执行该结点。当遍历集合时,会通过头指针一直遍历到尾指针,此时就实现了存取数据顺序一致
使用迭代器遍历LinkedHashSet集合的底层源码分析 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 package com.itcz;import java.util.Iterator;import java.util.LinkedHashSet;public class Set08 { @SuppressWarnings({"all"}) public static void main (String[] args) { LinkedHashSet linkedHashSet = new LinkedHashSet (); linkedHashSet.add("Java" ); linkedHashSet.add("Php" ); linkedHashSet.add("JavaScript" ); Iterator iterator = linkedHashSet.iterator(); while (iterator.hasNext()) { Object next = iterator.next(); System.out.println(next); } } }
TreeSet
基本介绍 :
底层维护的是一个红黑树的数据结构存储数据
TreeSet 是 TreeMap 的子类,故而底层存储的还是键值对,只是使用了PRESENT属性对value值进行了占位
存储的元素不重复、无索引、可排序
对于数值类型,默认按照从小到大得顺序进行排序
对于字符、字符串类型,则是按照字符在ASCII码表中得数字升序进行排序
第一种自定义排序规则来控制TreeSet集合的排序 :
让类实现Comparable接口,并重写compareTo方法
红黑树会循环调用重写的compareTo方法来找到要存储的结点在红黑树中的位置,并在结点添加后按照平衡规则对红黑树的结构进行调整
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 import java.util.Iterator;import java.util.TreeSet;public class Set10 { public static void main (String[] args) { TreeSet<Student> ts = new TreeSet <>(); ts.add(new Student ("zhangsan" , 24 )); ts.add(new Student ("lisi" , 23 )); ts.add(new Student ("wangwu" , 22 )); for (Student next : ts) { System.out.println(next); } } } class Student implements Comparable <Student> { private String name; private int age; public Student (String name, int age) { this .name = name; this .age = age; } public String getName () { return name; } public void setName (String name) { this .name = name; } public int getAge () { return age; } public void setAge (int age) { this .age = age; } @Override public String toString () { return "Student{" + "name='" + name + '\'' + ", age=" + age + '}' ; } @Override public int compareTo (Student o) { return this .getAge() - o.getAge(); } }
第二种自定义排序规则来控制TreeSet集合的排序 :
创建TreeSet对象时,传递实现了比较器Comparator接口的对象
红黑树会循环调用重写的compare方法来找到要存储的结点在红黑树中的位置,并在结点添加后按照平衡规则对红黑树的结构进行调整
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 import java.util.Comparator;import java.util.Iterator;import java.util.TreeSet;public class Set11 { public static void main (String[] args) { TreeSet<String> ts = new TreeSet <>((o1, o2) -> o1.length() - o2.length() == 0 ? o1.compareTo(o2) : o1.length() - o2.length()); ts.add("hello" ); ts.add("world" ); ts.add("a" ); ts.add("ab" ); ts.add("abc" ); for (String str : ts) { System.out.println(str); } } }
Map
基本介绍 :
Map 接口用于保存具有映射关系的数据:key-value
Map 中的 key 和 value 可以是任何引用类型的数据,会封装到HashMap的静态内部类Node对象中
Map 中的 key 不可以重复,原因是底层源码中重复的key的数据不会添加到集合中,但是默认会替换旧的value值
Map 中 value 可以重复
Map 中 key 可以为 null,value 也可以为 null,但是值为 null 的 key 只能有一个,而值为 null 的 value 可以有多个
一般使用 String 类作为 Map 的 key
key 与 value 之间存在单向一对一关系,即通过指定的 key 总能找到对应的 value
常用方法 :
put(Object o):添加数据
remove(Ojbect key):根据键删除映射关系
get(Ojbect key):根据键获取值
size():获取元素个数
isEmpty():判断元素个数是否为0
clear():清空元素
containsKey(Object key):查找键是否存在
keySet():获取KeySet类的对象,进而可以遍历集合中的每个元素的key
entrySet():获取EntrySet类的对象,进而可以遍历集合中每个元素
values():获取Values类的对象,进而可以遍历集合中每个元素的value
HashMap
基本介绍 :
存储键值对key-value
存取顺序不一致,但是每次遍历集合的顺序都是一致的,因为它是通过遍历数组+链表来取出数据,通过计算hash值在数组中的索引值来存储数据
key值唯一,value值可重复,并且都能为null
底层结构 :
链表结点Node定义如下,它是HashMap的静态内部类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 static class Node <K,V> implements Map .Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) { this .hash = hash; this .key = key; this .value = value; this .next = next; } public final K getKey () { return key; } public final V getValue () { return value; } public final String toString () { return key + "=" + value; } public final int hashCode () { return Objects.hashCode(key) ^ Objects.hashCode(value); } public final V setValue (V newValue) { V oldValue = value; value = newValue; return oldValue; } public final boolean equals (Object o) { if (o == this ) return true ; if (o instanceof Map.Entry) { Map.Entry<?,?> e = (Map.Entry<?,?>)o; if (Objects.equals(key, e.getKey()) && Objects.equals(value, e.getValue())) return true ; } return false ; } }
数组table的定义如下,默认是null,它是HashMap的属性
1 transient Node<K,V>[] table;
添加数据时的扩容机制 :
HashMap的无参构造方法会设置加载因子为0.75
添加元素时,如果table数组为null,则会进行第一次扩容,此时数组长度会扩容到16个,并设置数组阈值为12(16 * 0.75),如果不为null,会通过哈希算法得到一个hash值,再将数组table长度 - 1 与哈希值进行按位与运算得到索引
得到索引后会通过索引找到该索引在数组table中的位置,判断该数组位置上是否有元素
如果没有,则直接添加到数组中,如果有,则调用equals方法进行比较key值,如果相同就替换value值,如果不同,则添加到链表最后
添加成功后会将存储元素总个数 + 1,并对比总个数 和 数组的阈值,超过了会对数组table进行扩容,扩容后的数组长度为原来的两倍,并将数组阈值设置为原来的两倍
如果旧数组不为null,则会将旧数组的元素按照下列规则拷贝到新数组中
如果旧数组元素为单个结点(即链表中只有一个结点),则按照hash值与新数组长度 - 1按位与得到该元素在新数组的索引值
如果就数组元素类型为红黑树,则按照红黑树的规则进行拆分红黑树
如果数组元素不为单个结点(即链表中不止一个结点),此时会通过计算链表中每个结点的hash值与旧数组的长度进行按位与运算的结果,判断该结果是否为0
为0,则将该元素添加到低位链表(新创建)的最后
不为0,则将该元素添加到高位链表(新创建)的最后
- 最后将低位链表添加到新数组[旧索引],高位链表添加到新数组[旧索引 + 旧数组长度]
在Java8中,插入元素后,如果一条链表的长度大于等于了TREEIFY_THRESHOLD(默认为8),并且数组table的大小大于等于了MIN_TREEIFY_CAPACITY(默认64),就会进行树化(红黑树)
使用迭代器遍历HashMap集合的源码分析 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 import java.util.*;public class Map01 { @SuppressWarnings({"all"}) public static void main (String[] args) { Map map = new HashMap <>(); map.put("no1" , "陈洲" ); map.put("no2" , "奥数定理" ); Set set = map.entrySet(); Iterator iterator = set.iterator(); while (iterator.hasNext()) { Object next = iterator.next(); System.out.println(next); } } }
通过HashMap的entrySet方法可以获取到EntrySet(HashMap类的成员内部类)对象,通过该对象可以根据数据删除HashMap中对应的单链表结点,还可以获取EntryIterator(HashMap类的成员内部类)对象(迭代器),通过该迭代器可以获取HashMap中每个单链表结点
使用迭代器获取HashMap中每个单链表结点的key值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 package com.itcz;import java.util.HashMap;import java.util.Iterator;import java.util.Map;import java.util.Set;public class Map02 { @SuppressWarnings({"all"}) public static void main (String[] args) { Map map = new HashMap <>(); map.put("no1" , "陈洲" ); map.put("no2" , "奥数定理" ); Set set = map.keySet(); Iterator iterator = set.iterator(); while (iterator.hasNext()) { Object next = iterator.next(); System.out.println(next); } } }
通过HashMap的keySet方法可以获取到KeySet(HashMap类的成员内部类)对象,通过该对象可以根据传入的key值删除HashMap中对应的单链表结点,还可以获取KeyIterator(HashMap类的成员内部类)对象(迭代器),通过该迭代器可以获取HashMap中每个单链表结点的key值
使用迭代器获取HashMap中每个单链表结点的value值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 import java.util.*;public class Map03 { @SuppressWarnings({"all"}) public static void main (String[] args) { Map map = new HashMap <>(); map.put("no1" , "陈洲" ); map.put("no2" , "奥数定理" ); Collection collection = map.values(); Iterator iterator = collection.iterator(); while (iterator.hasNext()) { Object next = iterator.next(); System.out.println(next); } } }
通过HashMap的values方法可以获取到Values(HashMap类的成员内部类)对象,通过该对象可以根据传入的value值删除HashMap中对应的单链表结点,还可以获取ValueIterator(HashMap类的成员内部类)对象(迭代器),通过该迭代器可以获取HashMap中每个单链表结点的value值
LinkedHashMap
基本介绍 :
存储键值对key-value
存取顺序一致,因为底层是用双向链表来控制存取顺序
key值唯一,value值可重复,key和value都可以为null
底层结构 :
双向链表结点Entry定义如下,它是LinkedHashMap的静态内部类,并且继承了父类HashMap中的静态内部类Node,故而table表中可以存储双向链表的结点
1 2 3 4 5 6 static class Entry <K,V> extends HashMap .Node<K,V> { Entry<K,V> before, after; Entry(int hash, K key, V value, Node<K,V> next) { super (hash, key, value, next); } }
数组table的定义如下,默认是null,它是HashMap的属性
1 transient Node<K,V>[] table;
首尾指针定义如下,默认是null,它是LinkedHashMap的属性
1 2 3 4 5 6 transient LinkedHashMap.Entry<K,V> head;transient LinkedHashMap.Entry<K,V> tail;
添加数据时的扩容机制 :
LinkedhashMap的无参构造方法会调用其父类的HashMap的无参构造方法,该方法会将加载因子设为0.75
添加元素时,如果table数组为null,则会进行第一次扩容,此时数组长度会扩容到16个,并设置数组阈值为12(16 * 0.75),如果不为null,会通过哈希算法得到一个hash值,再将数组table长度 - 1 与哈希值进行按位与运算得到索引
得到索引后会通过索引找到该索引在数组table中的位置,判断该数组位置上是否有元素
如果没有,则直接添加到数组table中并且添加到双向链表的最后,如果有,则调用equals方法进行比较key值,如果相同就替换value值,如果不同,则添加到单链表(该索引所在的链表)的最后并添加到双向链表最后
添加成功后会将存储元素总个数 + 1,并对比总个数 和 数组的阈值,超过了会对数组table进行扩容,扩容后的数组长度为原来的两倍,并将数组阈值设置为原来的两倍
如果旧数组不为null,则会将旧数组的元素按照下列规则拷贝到新数组中
如果旧数组元素为单个结点(即单链表中只有一个结点),则按照hash值与新数组长度 - 1按位与得到该元素在新数组的索引值
如果就数组元素类型为红黑树,则按照红黑树的规则进行拆分红黑树
如果数组元素不为单个结点(即单链表中不止一个结点),此时会通过计算单链表中每个元素的hash值与旧数组的长度进行按位与运算的结果,判断该结果是否为0
为0,则将该元素添加到低位链表(新创建)的最后
不为0,则将该元素添加到高位链表(新创建)的最后
- 最后将低位链表添加到新数组[旧索引],高位链表添加到新数组[旧索引 + 旧数组长度]
在Java8中,插入元素后,如果一条链表的长度大于了TREEIFY_THRESHOLD(默认为8),并且数组table的大小大于等于了MIN_TREEIFY_CAPACITY(默认64),就会进行树化(红黑树)
使用迭代器遍历LinkedHashMap集合的源码分析 :
使用迭代器获取LinkedHashMap中每个双向链表结点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 package com.itcz;import java.util.*;public class Map04 { @SuppressWarnings({"all"}) public static void main (String[] args) { Map map = new LinkedHashMap (); map.put("no1" , "陈洲" ); map.put("no2" , "奥数定理" ); Set set = map.entrySet(); Iterator iterator = set.iterator(); while (iterator.hasNext()) { Object next = iterator.next(); System.out.println(next); } } }
通过LinkedHashMap的entrySet方法可以获取到LinkedEntrySet(LinkedHashMap类的成员内部类)对象,通过该对象可以根据数据删除LinkedHashMap中对应的双向链表结点,还可以获取LinkedEntryIterator(LinkedHashMap类的成员内部类)对象(迭代器),通过该迭代器可以获取LinkedHashMap中每个双向链表结点
使用迭代器获取LinkedHashMap中每个双向链表结点的key值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 import java.util.Iterator;import java.util.LinkedHashMap;import java.util.Map;import java.util.Set;public class Map05 { @SuppressWarnings({"all"}) public static void main (String[] args) { Map map = new LinkedHashMap (); map.put("no1" , "陈洲" ); map.put("no2" , "奥数定理" ); Set set = map.keySet(); Iterator iterator = set.iterator(); while (iterator.hasNext()) { Object next = iterator.next(); System.out.println(next); } } }
通过LinkedHashMap的keySet方法可以获取到LinkedKeySet(LinkedHashMap类的成员内部类)对象,通过该对象可以根据传入key值删除LinkedHashMap中对应的双向链表结点,还可以获取LinkedKeyIterator(LinkedHashMap类的成员内部类)对象(迭代器),通过该迭代器可以获取LinkedHashMap中每个双向链表结点的key值
使用迭代器获取LinkedHashMap中每个双向链表结点的value值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 import java.util.*;public class Map06 { @SuppressWarnings({"all"}) public static void main (String[] args) { Map map = new LinkedHashMap (); map.put("no1" , "陈洲" ); map.put("no2" , "奥数定理" ); Collection collection = map.values(); Iterator iterator = collection.iterator(); while (iterator.hasNext()) { Object next = iterator.next(); System.out.println(next); } } }
通过LinkedHashMap的values方法可以获取到LinkedValues(LinkedHashMap类的成员内部类)对象,通过该对象可以根据传入的value值删除LinkedHashMap中对应的双向链表结点,还可以获取LinkedValueIterator(LinkedHashMap类的成员内部类)对象(迭代器),通过该迭代器可以获取LinkedHashMap中每个双向链表结点的value值
Hashtable
基本介绍 :
存放的元素是键值对:即K-V
底层结构采用数组+链表来存储数据,没有红黑树
Hashtable的键和值都不能为null,否则会抛出NullPointerException
Hashtable 使用方法基本上和HashMap一样
Hashtable是线程安全的(synchronized),HashMap是线程不安全的
底层结构 :
数组table的定义如下,默认是null,它是Hashtable的属性
1 private transient Entry<?,?>[] table;
单链表类型定义如下,它是Hashtable的静态内部类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 private static class Entry <K,V> implements Map .Entry<K,V> { final int hash; final K key; V value; Entry<K,V> next; protected Entry (int hash, K key, V value, Entry<K,V> next) { this .hash = hash; this .key = key; this .value = value; this .next = next; } @SuppressWarnings("unchecked") protected Object clone () { return new Entry <>(hash, key, value, (next==null ? null : (Entry<K,V>) next.clone())); } public K getKey () { return key; } public V getValue () { return value; } public V setValue (V value) { if (value == null ) throw new NullPointerException (); V oldValue = this .value; this .value = value; return oldValue; } public boolean equals (Object o) { if (!(o instanceof Map.Entry)) return false ; Map.Entry<?,?> e = (Map.Entry<?,?>)o; return (key==null ? e.getKey()==null : key.equals(e.getKey())) && (value==null ? e.getValue()==null : value.equals(e.getValue())); } public int hashCode () { return hash ^ Objects.hashCode(value); } public String toString () { return key.toString()+"=" +value.toString(); } }
添加数据的扩容机制 :
Hashtable的无参构造方法会调用其有参构造方法,将数组大小设置为11,设置加载因子为0.75,故而数组阈值为8
添加数据时,会先通过hashCode方法获取到hash值,后将hash值与 0x7FFFFFFF(int类型的最大正整数值) 进行按位与运算(保证hash值为正数),最后将处理后的hash值 % 数组的长度得到索引值
遍历索引值所在数组元素的单链表,如果有单链表结点中存储的key值与要添加的key值一致,则替换该结点中的value值,并返回替换前的value值
否则将数据通过头插法添加到该链表的首部,但是在添加之前会先判断集合中存储的元素个数是否大于等于数组阈值,如果满足条件,会先对数组进行扩容处理,扩容后会重新计算索引值,故而先判断后添加
扩容后的数组大小为原来的数组大小 * 2 + 1,阈值为扩容后的数组大小 * 0.75,将旧数组中数据拷贝到新数组的规则如下:
依次遍历旧数组的数组元素,每次遍历过程中还要遍历该数组元素所在的单链表,通过该单链表中每个结点存储的hash值重新计算索引值,并将其通过头插法插入到新数组中索引值所在的单链表中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 for (int i = oldCapacity ; i-- > 0 ;) { for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) { Entry<K,V> e = old; old = old.next; int index = (e.hash & 0x7FFFFFFF ) % newCapacity; e.next = (Entry<K,V>)newMap[index]; newMap[index] = e; } }
Properties
基本介绍 :
Properties类继承自Hashtable类并且实现了Map接口,也是使用一种键值对的形式来保存数据。
键和值都不能为null,如果添加数据时存在相同的key,则会对value进行替换
Properties 还可以用于 从xxx.properties文件中,加载数据到Properties类对象,并进行读取和修改
常用方法 :
get(Ojbect key):根据键获取值
load(Reader reader/ InputStream is):加载配置文件的键值对到Properties对象
lit(PrintStream printStream/ PrintWriter printWriter):将数据显示到指定设备
getProperty(Ojbect key):根据键获取值
setProperty(Object key, Object value):设置键值对到properties对象
store(Writer writer, String comments) 或者 store(OutputStream out, String comments):将Properties中的键值对存储到配置文件,在idea中,保存信息到配置文件,如果含有中文,会存储为unicode码
remove(Objcet key):根据键删除键值对
put(Object key, Object value):如果key存在,则替换vlaue(改),如果key不存在,则将键值对添加到集合中(增)
TreeMap
基本介绍 :
TreeMap跟TreeSet底层原理一样,都是红黑树结构的。
由键决定特性:不重复、无索引、可排序
可排序:对键进行排序。
注意:默认按照键的从小到大进行排序,也可以自定义键的排序规则
自定义排序规则的方式有两种 :
类实现Comparable接口,重写compareTo方法
创建TreeMap对象时,通过构造器传递实现了Comparator接口并重写了compare方法的对象(可以通过匿名内部类进行传递)
Collections 工具类 常用方法(都是静态方法 ):
方法名称 说明
public static boolean addAll(Collection c, T … elements)
批量添加元素
public static void shuffle(List <? > list)
打乱List集合元素的顺序
public static void reverse(List <? > list)
反转List集合元素顺序
public static void sort(List list)
排序
public static void sort(List list, Comparator c)
根据指定的规则进行排序
public static int binarySearch (List list, T key)
以二分查找法查找元素
public static void copy(List dest, List src)
拷贝集合中的元素
public static int fill (List list, T obj)
使用指定的元素填充集合
public static void max/min(Collection coll)
根据默认的自然排序获取最大/小值
public static void swap(List <? > list, int i, int j)
交换集合中指定位置的元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 import java.util.ArrayList;import java.util.Collection;import java.util.Collections;import java.util.Comparator;@SuppressWarnings({"all"}) public class CollectionsTest { public static void main (String[] args) { Collection collection = new ArrayList (); Collections.addAll(collection, "java" , "php" , "vue" , "spring" ); System.out.println("批量添加后的集合元素为" + collection); ArrayList arrayList = (ArrayList) collection; Collections.shuffle(arrayList); System.out.println("打乱顺序后的集合元素为" + arrayList); Collections.sort(arrayList); System.out.println("按照字母顺序进行排序后的集合元素为" + arrayList); Collections.sort(arrayList, (o1, o2) -> ((String)o1).length() - ((String)o2).length()); System.out.println("按照字符串长度进行排序后的集合元素为" + arrayList); int phpIndex = Collections.binarySearch(arrayList, "php" ); System.out.println("根据二分查找法找到字符串php在集合中的位置为" + phpIndex); ArrayList newArrayList = new ArrayList (arrayList.size()); for (int i = 0 ; i < arrayList.size(); i++) { newArrayList.add(null ); } Collections.copy(newArrayList, arrayList); System.out.println("拷贝集合中的元素得到的新集合中的元素为" + newArrayList); Collections.fill(newArrayList, "java" ); System.out.println("用字符串java填充集合后的集合元素为" + newArrayList); String minStr = (String) Collections.min(arrayList); System.out.println("根据添加的数据的运行类型的默认排序顺序获取的最小值为" + minStr); String maxStr = (String) Collections.max(arrayList); System.out.println("根据添加的数据的运行类型的默认排序顺序获取的最大值为" + maxStr); Collections.swap(arrayList, 0 , 1 ); System.out.println("交换集合中第一个元素和第二个元素" + arrayList); } }
Stream 流
基本介绍 :
Stream 流负责将集合或者数组中的数据转换为流,Stream 流提供了一系列的API,该API可以对流进行操作,最后可以得到处理完的数据
Stream 流提供了两类方法:中间方法和终结方法
将数据转换为流的方法如下 :
获取方式 方法名 说明
单列集合 default Stream stream()
Collection中的默认方法
双列集合 无
无法直接使用stream流
数组 public static Stream stream(T[] array)
Arrays工具类中的静态方法
一堆零散数据 public static Stream of(T … values)
Stream接口中的静态方法
零散数据要求是同种类型的数据
Strem接口中的静态方法of的细节:方法的形参是一个可变参数,可以传递一堆零散数据,可以传递数组,但是数组必须保存的是引用数据类型的数据,如果保存的是基本数据类型,底层不会把数组中的每个元素进行自动装箱,而是会把整个数组作为一个元素放在stream流中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 import java.util.*;import java.util.function.Consumer;import java.util.stream.Stream;public class Test { public static void main (String[] args) { ArrayList<String> list = new ArrayList <>(); Collections.addAll(list, "a" , "b" , "c" , "d" , "e" ); list.stream().forEach(s -> System.out.println(s)); System.out.println("==============================================================" ); HashMap<String, Integer> hashMap = new LinkedHashMap <>(); hashMap.put("aaa" , 111 ); hashMap.put("bbb" , 222 ); hashMap.put("ccc" , 333 ); hashMap.put("ddd" , 444 ); hashMap.entrySet().stream().forEach(s -> System.out.println(s)); hashMap.keySet().stream().forEach(s -> System.out.println(s)); hashMap.values().stream().forEach(s -> System.out.println(s)); System.out.println("==============================================================" ); int [] arr = {1 , 2 , 3 , 4 , 5 , 6 }; Arrays.stream(arr).forEach(s -> System.out.println(s)); Stream.of(arr).forEach(s -> System.out.println(s)); System.out.println("==============================================================" ); Stream.of("1" , "2" , "3" , "4" , "5" ).forEach(s -> System.out.println(s)); } }
中间方法 :
名称 说明
Stream filter(Predicate <? super T> predicate)
过滤
Stream limit(long maxSize)
获取前几个元素
Stream skip(long n)
跳过前几个元素
Stream distinct()
元素去重,依赖(hashCode和equals方法)
static Stream concat(Stream a, Stream b)
合并a和b两个流为一个流
Streammap(Function<T , R> mapper)
转换流中的数据类型
Optional reduce(BinaryOperator accumulator) 聚合流中的各个数据,聚合的含义就是将多个值经过特定计算之后得到单个值(Optional类中有get方法可以直接获取到计算后的单个值)
注意:
中间方法,返回新的Stream流,原来的Stream流只能使用一次,建议使用链式编程
修改Stream流中的数据,不会影响原来集合或者数组中的数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 import java.util.ArrayList;import java.util.Arrays;import java.util.Collections;import java.util.function.Function;import java.util.function.Predicate;import java.util.stream.Stream;public class Test02 { public static void main (String[] args) { ArrayList<String> list = new ArrayList <>(); Collections.addAll(list, "张无忌" , "张三" , "周芷若" , "孙悟空" , "张铁" , "韩立" ); list.stream() .filter(s -> s.startsWith("张" )) .forEach(s -> System.out.println(s)); System.out.println("==============================================" ); list.stream() .limit(3 ) .forEach(s -> System.out.println(s)); System.out.println("==============================================" ); list.stream() .skip(3 ) .forEach(s -> System.out.println(s)); System.out.println("==============================================" ); list.add("张无忌" ); list.add("张无忌" ); list.add("张无忌" ); list.add("张无忌" ); list.stream() .distinct() .forEach(s -> System.out.println(s)); System.out.println("==============================================" ); ArrayList<String> list1 = new ArrayList <>(); Collections.addAll(list1, "李四" , "王五" ); Stream.concat(list.stream(), list1.stream()).forEach(s -> System.out.println(s)); System.out.println("=========================================================" ); ArrayList<String> list2 = new ArrayList <>(); Collections.addAll(list2, "张无忌-12" , "张三-45" , "周芷若-58" , "孙悟空-20" , "张铁-23" , "韩立-56" ); list2.stream() .map(s -> Integer.parseInt(s.split("-" )[1 ])) .forEach(s -> System.out.println(s)); List<Integer> list3 = Lists.newArrayList(1 ,2 ,3 ,4 ,5 ); Integer total = list3.stream().reduce((result,item)->result+item).get(); System.out.println(total); } }
终结方法 :
名称 说明
void forEach(Consumer action)
遍历
long count()
统计
toArray()
收集流中的数据,放到数组中
collect(Collector collector)
收集流中的数据,放到集合中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 import java.util.ArrayList;import java.util.Arrays;import java.util.Collections;import java.util.function.Consumer;import java.util.function.IntFunction;public class Test03 { public static void main (String[] args) { ArrayList<String> list = new ArrayList <>(); Collections.addAll(list, "张无忌" , "张三" , "周芷若" , "孙悟空" , "张铁" , "韩立" ); list.stream() .forEach(s -> System.out.println(s)); System.out.println("=================================================" ); long count = list.stream().count(); System.out.println("list中元素个数为" + count); System.out.println("=================================================" ); Object[] array = list.stream().toArray(); System.out.println(Arrays.toString(array)); String[] strs = list.stream().toArray(value -> new String [value]); System.out.println(Arrays.toString(strs)); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 import java.util.*;import java.util.function.Function;import java.util.stream.Collectors;public class Test04 { public static void main (String[] args) { ArrayList<String> list = new ArrayList <>(); Collections.addAll(list, "张无忌-男-12" , "张三-女-45" , "周芷若-女-58" , "孙悟空-男-20" , "张铁-男-23" , "韩立-男-56" , "李四-女-28" , "王五-男-29" ); List<String> list1 = list.stream() .filter(s -> "男" .equals(s.split("-" )[1 ])) .collect(Collectors.toList()); System.out.println(list1); System.out.println("=================================================" ); Set<String> set = list.stream() .filter(s -> "男" .equals(s.split("-" )[1 ])) .collect(Collectors.toSet()); System.out.println(set); System.out.println("=================================================" ); Map<String, Integer> map = list.stream() .filter(s -> "男" .equals(s.split("-" )[1 ])) .collect(Collectors.toMap(s -> s.split("-" )[0 ], s -> Integer.parseInt(s.split("-" )[2 ]))); System.out.println(map); } }
泛型
基本介绍 :
泛型又称为参数化类型,是JDK1.5出现的新特性,解决数据类型的安全性问题
在类声明或示例化时只要指定好需要的具体类型
泛型的作用:可以在声明类时通过一个标识标识类中某个属性的类型,或者是某个方法的返回值的类型,或者是参数类型
泛型的使用 :
1 2 interface 接口名<T> {} class 类名<K, V> {}
1 2 3 类名<数据类型> 对象名 = new 类名<数据类型>(); 或者 类名<数据类型> 对象名 = new 类名<>();
使用细节 :
给泛型指定数据类型时,要求时引用类型,不能是基本数据类型
给泛型指定具体类型后,可以传入该类型或者其子类型
如果不给泛型指定具体类型,则泛型默认是Object
自定义泛型类
基本语法 :
1 2 3 class 类名<T, R, ...> { }
使用细节 :
普通成员可以使用泛型(方法、属性)
使用泛型的数组,不能初始化(因为不确定类型,就无法在JVM内存中开辟空间)
静态成员中不能使用类的泛型,因为静态方法和属性在类加载时就会加载,而创建对象是在类加载之后,所以如果静态方法或者属性使用了泛型,JVM无法完成初始化
泛型类中的泛型的类型是在创建对象时确定的(因为创建对象时,需要指定确定类型)
如果在创建对象时,没有指定类型,则默认为Object类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 public class Generic01 { public static void main (String[] args) { Person<String, Integer> person = new Person <>("zhangsan" , 18 ); System.out.println(person.getR()); System.out.println(person.getT()); person.setR(20 ); person.setT("lisi" ); System.out.println(person); } } class Person <T, R> { T t; R r; public Person (T t, R r) { this .t = t; this .r = r; } public T getT () { return t; } public void setT (T t) { this .t = t; } public R getR () { return r; } public void setR (R r) { this .r = r; } @Override public String toString () { return "Person{" + "t=" + t + ", r=" + r + '}' ; } }
自定义泛型接口
基本语法 :
1 2 3 interface 接口名<T, R, ...> { }
使用细节 :
接口中,静态成员也不能使用泛型,原因和泛型类一致
泛型接口的类型,在继承接口或者实现接口时确定
没有指定类型,默认为Object类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 public class Generic02 { public static void main (String[] args) { } } interface IA extends IUsb <String, Double> { } class A implements IA { @Override public String run (String s, Double aDouble) { return "" ; } @Override public void print (String t1, String t2, Double r1, Double r2) { } } class B implements IUsb <Float, Double> { @Override public Float run (Float aFloat, Double aDouble) { return 0f ; } @Override public void print (Float t1, Float t2, Double r1, Double r2) { } } interface IUsb <T, R> { int n = 10 ; T run (T t, R r) ; void print (T t1, T t2, R r1, R r2) ; }
自定义泛型方法
基本语法:
1 2 3 访问修饰符 <T, R, ...> 返回类型 方法名(形参列表) { }
使用细节:
泛型方法可以定义在普通类中,也可以定义在泛型类中
当泛型方法被调用时,类型就会被确认
public void eat(E e) {},修饰符后没有<T, R, …>,eat方法不是泛型方法,而是eat方法使用了泛型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 public class Generic03 { public static void main (String[] args) { Car<String, Double> car = new Car <>(); car.run("宝马" , 18.2 ); System.out.println("========" ); car.fly("宝马" , "A7" , 28.2 ); System.out.println("========" ); car.fly(28 , "宝马" , 28.2 ); System.out.println("========" ); Dog dog = new Dog (); dog.run("你好" , new ArrayList <>()); } } class Car <T, R> { public void run (T t, R r) { System.out.println(t.getClass()); System.out.println(r.getClass()); } public <E> T fly (E e, T t, R r) { System.out.println(e.getClass()); System.out.println(t.getClass()); System.out.println(r.getClass()); return t; } } class Dog { public <T, R> void run (T t, R r) { System.out.println(t.getClass()); System.out.println(r.getClass()); } }
泛型的继承和通配符 基本介绍 :
:支持任意泛型类型
:支持A类以及A类的子类,规定了泛型的上限
:支持A类以及A类的父类,但并不限于直接父类,规定了泛型的下限
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 package com.itcz.generic;import java.util.ArrayList;import java.util.List;public class Generic04 { public static void main (String[] args) { List<Object> list1 = new ArrayList <>(); List<String> list2 = new ArrayList <>(); List<AA> list3 = new ArrayList <>(); List<BB> list4 = new ArrayList <>(); List<CC> list5 = new ArrayList <>(); collection1(list1); collection1(list2); collection1(list3); collection1(list4); collection1(list5); collection2(list3); collection2(list4); collection2(list5); collection3(list1); collection3(list3); } public static void collection1 (List<?> list) { } public static void collection2 (List<? extends AA> list) { } public static void collection3 (List<? super AA> list) { } } class AA {} class BB extends AA {} class CC extends BB {}
Optional 类
基本概念 :Optional 类(java.util.Optional)是一个容器类,它可以保存类型T的值,代表这个值存在,或者仅仅保存null,表示这个值不存在。原来用null表示一个值不存在,现在 Optional 可以更好的表达这个概念,并且可以有效避免空指针异常 常用方法 :
方法名 说明
public static of(T t)
创建一个 Optional 实例,t必须非空
public static empty()
创建一个空的 Optional 实例
public static ofNullable(T t)
创建一个 Optional 实例,t可以为null
T orElse(T other)
如果有值则将其返回,否则返回指定的other对象
T get()
如果调用对象包含值,则返回该值,否则会报空指针异常
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 import java.util.Optional;public class Test01 { public static void main (String[] args) { Dog dog = new Dog (); dog = null ; Optional<Dog> optionalDog = Optional.ofNullable(dog); System.out.println(optionalDog); Dog tom = optionalDog.orElse(new Dog ("tom" , 18 )); System.out.println(tom); } } class Dog { private String name; private int age; public Dog () { } public Dog (String name, int age) { this .name = name; this .age = age; } public String getName () { return name; } public void setName (String name) { this .name = name; } public int getAge () { return age; } public void setAge (int age) { this .age = age; } @Override public String toString () { return "Dog{" + "name='" + name + '\'' + ", age=" + age + '}' ; } }
方法引用
基本介绍 :把已经存在的方法的方法体作为函数式接口中的抽象方法的方法体要求 :
引用处必须是函数式接口
被引用的方法必须已经存在
被引用的方法的形参形式和返回值形式必须和抽象方法保持一致
被引用方法的功能要满足当前需求
引用静态方法 格式 :类名::方法名
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import java.util.ArrayList;import java.util.Collections;import java.util.function.Function;public class StaticMethod { public static void main (String[] args) { ArrayList<String> list = new ArrayList <>(); Collections.addAll(list, "1" , "2" , "3" , "4" , "5" ); list.stream() .map(Integer::parseInt) .forEach(s -> System.out.println(s)); } }
引用成员方法 格式 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import java.util.ArrayList;import java.util.Collections;import java.util.function.Predicate;public class FunctionDemo02 { public static void main (String[] args) { ArrayList<String> list = new ArrayList <>(); Collections.addAll(list, "张无忌" , "张三" , "周芷若" , "孙悟空" , "张铁" , "韩立" ); list.stream() .filter(new StringOperation ()::stringJudge) .forEach(s -> System.out.println(s)); } } class StringOperation { public boolean stringJudge (String s) { return s.startsWith("张" ) && s.length() == 3 ; } }
引用处不能是静态方法的内部,因为静态方法内部不能使用this关键字
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import java.util.ArrayList;import java.util.Collections;import java.util.function.Predicate;public class FunctionDemo03 { public static void main (String[] args) { new FunctionDemo03 ().method(); } public void method () { ArrayList<String> list = new ArrayList <>(); Collections.addAll(list, "张无忌" , "张三" , "周芷若" , "孙悟空" , "张铁" , "韩立" ); list.stream() .filter(this ::stringJudge) .forEach(s -> System.out.println(s)); } public boolean stringJudge (String s) { return s.startsWith("张" ) && s.length() == 3 ; } }
引用处不能是静态方法的内部,因为静态方法内部不能使用super关键字
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 import java.util.ArrayList;import java.util.Collections;public class FunctionDemo04 extends FatherClass { public static void main (String[] args) { new FunctionDemo04 ().method(); } public void method () { ArrayList<String> list = new ArrayList <>(); Collections.addAll(list, "张无忌" , "张三" , "周芷若" , "孙悟空" , "张铁" , "韩立" ); list.stream() .filter(super ::stringJudge) .forEach(s -> System.out.println(s)); } } class FatherClass { public boolean stringJudge (String s) { return s.startsWith("张" ) && s.length() == 3 ; } }
引用构造方法 格式 :类名::new
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 import java.util.ArrayList;import java.util.Collections;import java.util.List;import java.util.function.Function;import java.util.stream.Collectors;public class FunctionDemo05 { public static void main (String[] args) { ArrayList<String> list = new ArrayList <>(); Collections.addAll(list, "张三-18" , "李四-20" , "王五-21" , "赵六-45" , "孙悟空-456" ); List<Student> newList = list.stream().map(Student::new ).collect(Collectors.toList()); System.out.println(newList); } } class Student { private String name; private int age; public Student (String str) { String[] split = str.split("-" ); this .name = split[0 ]; this .age = Integer.parseInt(split[1 ]); } @Override public String toString () { return "Student{" + "name='" + name + '\'' + ", age=" + age + '}' ; } public String getName () { return name; } public void setName (String name) { this .name = name; } public int getAge () { return age; } public void setAge (int age) { this .age = age; } public Student (String name, int age) { this .name = name; this .age = age; } }
通过类名::方法名引用该类中的方法
注意 :通过类名::方法名引用该类中的方法时,该方法可以是静态方法,也可以是非静态方法要求 :
被引用的地方需要是函数式接口
被引用的方法必须已经存在
被引用方法的形参,需要跟抽象方法的第二个形参到最后一个形参保持一致,返回值类型需要保持一致
被引用方法的功能需要满足当前需求
函数式接口中的抽象方法形参详解
第一个参数:表示被引用方法的调用者,决定了可以引用哪些类中的方法,在stream流中,第一个参数一般表示流里面的每一个数据。例如流里面的数据的数据类型是String类型,那么使用这种方式进行方法引用时,只能引用String类中的方法
第二个参数到最后一个参数必须和被引用的形参列表保持一致,如果抽象方法中没有第二个参数,说明被引用的方法需要是无参的成员方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import java.util.ArrayList;import java.util.Collections;import java.util.function.Function;public class FunctionDemo06 { public static void main (String[] args) { ArrayList<String> list = new ArrayList <>(); Collections.addAll(list, "aaa" , "bbb" , "ccc" , "ddd" ); list.stream().map(new Function <String, String>() { @Override public String apply (String s) { return s.toUpperCase(); } }).forEach(s -> System.out.println(s)); list.stream().map(String::toUpperCase).forEach(s -> System.out.println(s)); } }
引用数组的构造方法 格式 :数据类型[]::new
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import java.util.ArrayList;import java.util.Arrays;import java.util.Collections;import java.util.function.IntFunction;public class FunctionDemo07 { public static void main (String[] args) { ArrayList<Integer> list = new ArrayList <>(); Collections.addAll(list, 1 , 2 , 3 , 4 , 5 ); Integer[] array = list.stream().toArray(Integer[]::new ); System.out.println(Arrays.toString(array)); } }
多线程基础 进程
基本介绍 :
进程是指运行中的程序,例如使用QQ程序,就操作系统会在计算机中创建一个进程,操作系统会为该进程分配内存空间
进程是程序的一次执行过程,或是正在运行的一个程序,是动态过程:有它本身的产生、存在和消亡的过程
并发 :同一时刻,多个任务交替执行,因为切换频率快,造成了“貌似同时”的错觉,单核CPU实现的多任务就是并发并行 :同一时刻,多个任务同时执行,多核CPU可以实现并行
线程
基本介绍 :
线程可以由线程或者进程创建,它是进程的一个实体
一个进程可以拥有多个线程
单线程:同一时刻,只允许执行一个线程
多线程:同一时刻,可以执行多个线程,比如:一个QQ进程,可以同时打开多个聊天窗口,一个迅雷进程,可以同时下载多个文件
通过继承Thread类创建线程类 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 public class Thread01 { public static void main (String[] args) { Cat cat = new Cat (); cat.start(); for (int i = 0 ; i < 6 ; i++) { System.out.println(Thread.currentThread().getName() + "线程正在执行" + (i + 1 )); try { Thread.sleep(1000 ); } catch (InterruptedException e) { throw new RuntimeException (e); } } } } class Cat extends Thread { @Override public void run () { int times = 0 ; do { System.out.println(Thread.currentThread().getName() + "线程正在打印:喵喵,我是一只小猫咪" + (++times)); try { Thread.sleep(1000 ); } catch (InterruptedException e) { throw new RuntimeException (e); } } while (times <= 8 ); } }
该程序在JVM底层执行过程:当Thread01类执行后,会在JVM内存中创建一个进程,然后执行main方法时,该进程会创建一个主线程,主线程执行到Cat cat = new Cat();语句时,主线程会创建一个子线程,主线程执行到cat.start();语句时,主线程会启动子线程,此时子线程会开始执行Cat类中的run方法,执行里面的逻辑,并且主线程不会被阻塞,在执行过程中主线程会被销毁(因为main方法执行完毕),但是此时进程不会被销毁,因为子线程还在执行,直到子线程执行完所有的业务逻辑后,进程才会被销毁
通过实现Runable接口创建线程类 :
由于Java只支持单继承,故而当某个类继承了其父类时,就无法通过继承Thread类来创建线程,故而引出了Runable接口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 package com.itcz.thread;public class Thread02 { public static void main (String[] args) { Dog tom = new Dog ("tom" , 18 ); Thread thread = new Thread (tom); thread.start(); } } class Dog extends Animal implements Runnable { public Dog (String name, double age) { super (name, age); } @Override public void run () { int times = 0 ; do { System.out.println("小狗" + this .getName() + "嗷嗷叫~~~" + (++times) + Thread.currentThread().getName()); try { Thread.sleep(1000 ); } catch (InterruptedException e) { throw new RuntimeException (e); } } while (times != 10 ); } } class Animal { private String name; private double age; public String getName () { return name; } public void setName (String name) { this .name = name; } public double getAge () { return age; } public void setAge (double age) { this .age = age; } public Animal (String name, double age) { this .name = name; this .age = age; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 package com.itcz.thread;public class Thread03 { public static void main (String[] args) { T1 t1 = new T1 (); t1.start(); T2 t2 = new T2 (); ThreadProxy threadProxy = new ThreadProxy (t2); threadProxy.start(); } } class ThreadProxy { private Runnable target; public ThreadProxy (Runnable target) { this .target = target; } public ThreadProxy () { } public void run () { if (this .target != null ) { target.run(); } } public void start () { start0(); } public void start0 () { this .run(); } } class T1 extends ThreadProxy { @Override public void run () { System.out.println("子线程执行T1类中的run方法" ); } } class T2 implements Runnable { @Override public void run () { System.out.println("子线程执行T2类中的run方法" ); } }
继承Thread类 和 实现Runnable接口的区别 :
继承Thread类实现多线程,不便于多个线程共享同一资源
而实现Runnable接口实现多线程,便于多个线程共享同一资源
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 package com.itcz.thread;public class Thread04 { public static void main (String[] args) { T3 t3 = new T3 (); Thread thread1 = new Thread (t3); Thread thread2 = new Thread (t3); thread1.start(); thread2.start(); } } class T3 implements Runnable { @Override public void run () { while (true ) { int times = 0 ; do { System.out.println(Thread.currentThread().getName() + "线程在执行" + (++times)); try { Thread.sleep(1000 ); } catch (InterruptedException e) { throw new RuntimeException (e); } } while (times <= 8 ); } } }
线程终止 :
线程终止可以通过两种方式实现
当线程完成任务后,会自动退出
可以让线程完成的任务根据条件一直循环下去,其他线程更改该条件就可以让该线程退出任务,进而终止线程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 public class Thread06 { public static void main (String[] args) { T t = new T (); t.start(); System.out.println("主线程休眠十秒" ); try { Thread.sleep(10 * 1000 ); } catch (InterruptedException e) { throw new RuntimeException (e); } t.setLoop(false ); } } class T extends Thread { private boolean loop = true ; @Override public void run () { while (loop) { System.out.println("T线程正在运行....." ); try { Thread.sleep(50 ); } catch (InterruptedException e) { throw new RuntimeException (e); } } } public void setLoop (boolean loop) { this .loop = loop; } }
线程的生命周期 :
new 状态:创建态,当该线程被创建好,但是未获取到它需要的资源时所处于的状态
Runnable 状态:可运行状态,又可被细分为就绪态和运行态,就绪态是指线程已获取到除CPU以外的资源所处于的状态,运行态则是指线程已获取到CPU,并且正在运行的状态
TimedWaiting 超时等待状态:当线程调用sleep(int time)方法、wait(int time)、LockSupport.parkNanos()、LockSupport.parkUntil()或者当其他线程加入时(其他线程类对象调用join(int time)方法),线程会处于超时等待状态。当时间结束后会进入可运行状态
Waiting 等待状态:当线程调用wait(),LockSupport.park()或者当其他线程加入时(其他线程类对象调用join()方法),线程会处于等待状态。当线程调用notify()、notifyAll()或者LockSupport.unpark()方法时,会进入可运行状态
Blocked 阻塞状态:当线程等待获取进入同步代码块的锁时,会进入阻塞态,获取到锁后会进入可运行状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public class Thread09 { public static void main (String[] args) { T6 t6 = new T6 (); System.out.println("线程所处的状态:" + t6.getState()); t6.start(); System.out.println("线程所处的状态:" + t6.getState()); for (int i = 0 ; i < 5 ; i++) { try { Thread.sleep(1000 ); } catch (InterruptedException e) { throw new RuntimeException (e); } System.out.println("线程所处的状态:" + t6.getState()); } System.out.println("线程所处的状态:" + t6.getState()); } } class T6 extends Thread { @Override public void run () { for (int i = 0 ; i < 5 ; i++) { try { Thread.sleep(1000 ); } catch (InterruptedException e) { throw new RuntimeException (e); } System.out.println("h1 " + i); } } }
Thread 线程类
基本介绍 :
Thread 类实现了 Runnable 接口,重写了其中的 run 方法
Thread 类中有一个 Runnable 接口类型的 target 属性,用来接收实现 Runnable 接口的类的对象引用,进而通过静态代理方式实现多线程
常用方法 :
setName(String name):设置线程名
getName():返回该线程的名称
start():使该线程开始执行,底层调用start0方法
run():调用线程对象的 run 方法
setPriority(int priority):更改线程优先级,优先级范围从1到10
getPriority():获取线程优先级
sleep(int time):让线程休眠指定毫秒数,静态方法
interrupt():中断线程,中断线程不是终止线程,只是让线程执行到该语句时,报一个异常
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public class Thread07 { public static void main (String[] args) { T4 t4 = new T4 (); t4.setName("tom" ); t4.start(); try { Thread.sleep(1000 ); } catch (InterruptedException e) { throw new RuntimeException (e); } for (int i = 0 ; i < 5 ; i++) { System.out.println("主线程正在运行" + i); } t4.interrupt(); } } class T4 extends Thread { @Override public void run () { while (true ) { for (int i = 0 ; i < 100 ; i++) { System.out.println(Thread.currentThread().getName() + "线程正在运行" + i); } try { Thread.sleep(20000 ); } catch (InterruptedException e) { System.out.println(Thread.currentThread().getName() + "线程被中断,退出休眠" ); } } } }
yield():线程的礼让。让出cpu,让其他线程执行,但礼让的时间不确定,所以也不一定礼让成功,静态方法
join():线程的插队。插队的线程一旦插队成功,则肯定先执行完插入的线程所有的任务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public class Thread08 { public static void main (String[] args) { T5 t5 = new T5 (); t5.start(); System.out.println("主线程让子线程加入,主线程等子线程执行完毕后再执行" ); Thread.yield (); System.out.println("主线程继续执行" ); for (int i = 0 ; i < 10 ; i++) { try { Thread.sleep(1000 ); } catch (InterruptedException e) { throw new RuntimeException (e); } System.out.println("主线程正在运行...." + (i)); } } } class T5 extends Thread { @Override public void run () { for (int i = 0 ; i < 10 ; i++) { try { Thread.sleep(1000 ); } catch (InterruptedException e) { throw new RuntimeException (e); } System.out.println("子线程正在运行...." + (i)); } } }
setDeamon(boolean flag):将该线程设置为守护线程
用户线程:也称为工作线程,一般都是任务执行完毕或者以通知方式终止
守护线程:一般是为工作线程服务,当所有的用户线程结束后,守护线程自动结束,比如:垃圾回收机制
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 package com.itcz.thread;public class Thread09 { public static void main (String[] args) { T6 t6 = new T6 (); t6.setDaemon(true ); t6.start(); for (int i = 0 ; i < 5 ; i++) { try { Thread.sleep(1000 ); } catch (InterruptedException e) { throw new RuntimeException (e); } System.out.println("主线程正在运行....." ); } } } class T6 extends Thread { @Override public void run () { for (;;) { try { Thread.sleep(1000 ); } catch (InterruptedException e) { throw new RuntimeException (e); } System.out.println("守护线程正在运行....." ); } } }
线程同步机制
基本介绍 :
在多线程中,一些敏感数据不允许被多个线程同时访问,此时就需要使用同步访问技术,以保证数据在任何时候,最多只有一个线程访问,以保证数据的完整性
当一个线程对某个内存地址进行操作时,其他线程都不允许对其进行操作,都会进入堵塞队列
实现同步的方式 :
可以在代码块上添加 synchronized 关键字
可以在方法上添加 synchronized 关键字,让该方法变成同步方法
1 2 3 访问修饰符 synchronized 返回类型 方法名(形参列表) { }
互斥锁 :
Java语言中,引入了对象互斥锁的概念,来保证共享数据操作的完整性。
每个对象都对应于一个可称为“互斥锁”的标记,这个标记用来保证在任一时刻,只能有一个线程访问该对象。
关键字synchronized 来与对象的互斥锁联系。当某个对象用synchronized修饰时,表明该对象在任一时刻只能由一个线程访问
同步的局限性:导致程序的执行效率要降低
同步方法(非静态的)的锁是加在this上,同步方法(静态的)的锁为当前类.class对象
非静态方法中的同步代码块的互斥锁可以加在this对象上,也可以是加在其他对象(要求多个线程必须操作的是同一个对象的同步方法)
静态方法中的同步代码块的互斥锁只能加在当前类.class对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 public class Thread05 { public static void main (String[] args) { SellTicket01 sellTicket01 = new SellTicket01 (); new Thread (sellTicket01).start(); new Thread (sellTicket01).start(); new Thread (sellTicket01).start(); new Thread (sellTicket01).start(); new Thread (sellTicket01).start(); } } class SellTicket01 implements Runnable { private static int ticketNum = 100 ; private boolean loop = true ; private final Object object = new Object (); @Override public void run () { while (this .loop) { sell(); } } public void sell () { synchronized ( object) { if (ticketNum > 0 ) { System.out.println(Thread.currentThread().getName() + "线程售出一张票,剩余票数为" + (--ticketNum)); } try { Thread.sleep(50 ); } catch (InterruptedException e) { throw new RuntimeException (e); } if (ticketNum <= 0 ) { System.out.println(Thread.currentThread().getName() + "线程结束" ); this .loop = false ; } } } public static void sell1 () { synchronized (SellTicket01.class) { } } }
死锁 :多个线程都占用了对方的锁资源,但是不肯相让,这就形成了死锁状态
线程池
基本介绍 :
当继承Thread类和实现Runnable接口的线程类的任务执行完毕后,该线程就会被销毁,当再次需要该线程时,又会重新去启动该线程,这会导致资源的浪费,启动线程也需要大量的时间
当某个任务需要线程进行处理时,线程池会分配给该任务一个线程,当任务结束后不会销毁该线程,有利于节约资源,每次分配时,会先判断线程池中是否有空闲线程,如果没有,会再次创建新的线程
可以通过Executors类来获取线程池对象 :
方法名称 说明
public static ExecutorService newCachedThreadPool()
创建一个没有上限的线程池
public static ExecutorService newFixedThreadPool(int nThreads)
创建有上限的线程池
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 import java.util.concurrent.Executor;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;public class Thread10 { public static void main (String[] args) { ExecutorService pool1 = Executors.newCachedThreadPool(); ExecutorService pool2 = Executors.newFixedThreadPool(3 ); pool1.submit(new MyRunnable ()); pool1.submit(new MyRunnable ()); pool1.submit(new MyRunnable ()); pool1.submit(new MyRunnable ()); pool2.submit(new MyRunnable ()); pool2.submit(new MyRunnable ()); pool2.submit(new MyRunnable ()); pool2.submit(new MyRunnable ()); pool1.shutdown(); pool2.shutdown(); } } class MyRunnable implements Runnable { @Override public void run () { for (int i = 1 ; i <= 100 ; i++) { System.out.println("pool----" + Thread.currentThread().getName() + "-------" + i); } } }
自定义线程池
可以通过ThreadPoolExecutor类的构造方法创建自定义线程池对象
自定义线程池处理任务的机制 :当任务需要线程时,会先给任务分配核心线程,当核心线程数量达到上限后,会让后续任务阻塞在阻塞队列中,当阻塞队列中的任务达到队列中的任务上限时,会创建临时线程处理后续任务(这些任务不是阻塞队列里面的,而是此时超过阻塞队列上限时,后续需要处理的任务),当核心线程和临时线程的总数达到线程池的最大线程数时,会采取任务拒绝策略处理后续任务形参列表 :
参数一:核心线程的数量(不能小于0)
参数二:线程池最大线程的数量(最大数量>=核心线程数量)
参数三:空闲时间(值)(不能小于0)
参数四:空闲时间(单位)(用TimeUnit枚举类指定)
空闲时间表示当临时线程等待该时间长度,都没有分配给任务时,会销毁该临时线程
参数五:阻塞队列(不能为null)
ArrayBlockingQueue:有界的阻塞队列
LinkedBlockingQueue:无界的阻塞队列,但不是真正的无界,最大为int的最大值
参数六:创建线程的方式(不能为null)
一般传入Executors.defaultThreadFactory()
参数七:要执行的任务过多时的解决方案(不能为null)
任务拒绝策略(静态内部类) :
任务拒绝策略 说明
ThreadPoolExecutor. AbortPolicy
默认策略:丢弃任务并抛出RejectedExecutionException异常
ThreadPoolExecutor. DiscardPolicy
丢弃任务,但是不抛出异常这是不推荐的做法
ThreadPoolExecutor.DiscardOldestPolicy
抛弃队列中等待最久的任务 然后把当前任务加入队列中
ThreadPoolExecutor.CallerRunsPolicy
调用任务的run()方法绕过线程池直接执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 import java.util.concurrent.ArrayBlockingQueue;import java.util.concurrent.Executors;import java.util.concurrent.ThreadPoolExecutor;import java.util.concurrent.TimeUnit;public class Thread11 { public static void main (String[] args) { ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor ( 3 , 6 , 60 , TimeUnit.SECONDS, new ArrayBlockingQueue <>(3 ), Executors.defaultThreadFactory(), new ThreadPoolExecutor .AbortPolicy() ); threadPoolExecutor.submit(new MyRunnable ()); threadPoolExecutor.submit(new MyRunnable ()); threadPoolExecutor.submit(new MyRunnable ()); threadPoolExecutor.submit(new MyRunnable ()); threadPoolExecutor.shutdown(); } } class MyRunnable implements Runnable { @Override public void run () { for (int i = 1 ; i <= 100 ; i++) { System.out.println("pool----" + Thread.currentThread().getName() + "-------" + i); } } }
IO 流 文件
概念 :文件就是保存数据的地方文件流 :数据在数据源(文件)和程序(内存)之间经历的路径
输入流:数据从数据源(文件)到程序(内存)的路径
输出流:数据从程序(内存)到数据源(文件)的路径
创建文件对象相关构造器和方法 :
new File(String pathname) // 根据路径构建一个File对象
new File(File parent,String child) // 根据父目录文件+子路径构建
new File(String parent,String child) // 根据父目录+子路径构建
createNewFile 创建新文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import java.io.File;import java.io.IOException;public class FileCreate { public static void main (String[] args) { File file1 = new File ("E:\\newFile1.txt" ); try { file1.createNewFile(); } catch (IOException e) { throw new RuntimeException (e); } File parentFile = new File ("E:\\" ); File file2 = new File (parentFile, "newFile2.txt" ); try { file2.createNewFile(); } catch (IOException e) { throw new RuntimeException (e); } String parentPath = "E:\\" ; String fileName = "newFile3.txt" ; File file3 = new File (parentFile, fileName); try { file3.createNewFile(); } catch (IOException e) { throw new RuntimeException (e); } } }
常用方法 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 import java.io.File;import java.io.IOException;public class FileInformation { public static void main (String[] args) { File file1 = new File ("E:\\newFile1.txt" ); try { file1.createNewFile(); } catch (IOException e) { throw new RuntimeException (e); } System.out.println("文件名字=" + file1.getName()); System.out.println("文件绝对路径=" + file1.getAbsoluteFile()); System.out.println("文件父级目录=" + file1.getParent()); System.out.println("文件大小(字节)=" + file1.length()); System.out.println("文件是否存在=" + file1.exists()); System.out.println("是不是一个文件=" + file1.isFile()); System.out.println("是不是一个目录=" + file1.isDirectory()); if (file1.exists()) { if (file1.delete()) { System.out.println("文件" + file1.getName() + "删除成功" ); } else { System.out.println("文件" + file1.getName() + "删除失败" ); } } else { System.out.println("文件不存在,无法删除" ); } String filePath = "E:\\demo1" ; File file2 = new File (filePath); if (file2.mkdir()) { System.out.println("一级目录" + file2.getName() + "创建成功" ); } else { System.out.println("一级目录" + file2.getName() + "创建失败" ); } File file3 = new File ("E:\\demo1\\a\\b\\c" ); if (file3.mkdirs()) { System.out.println("多级目录" + file3.getName() + "创建成功" ); } else { System.out.println("多级目录" + file3.getName() + "创建失败" ); } if (file2.exists()) { if (file2.delete()) { System.out.println("目录" + file2.getName() + "删除成功" ); } else { System.out.println("目录" + file2.getName() + "删除失败" ); } } else { System.out.println("目录不存在,无法删除" ); } } }
IO 流原理
I/O是Input/Output的缩写,I/O技术是非常实用的技术,用于处理数据传输。
Java程序中,对于数据的输入/输出操作以”流(stream)”的方式进行。
java.io包下提供了各种“流”类和接口,用以获取不同种类的数据,并通过方
输入input:读取外部数据(磁盘、光盘等存储设备的数据)到程序(内存)中。
输出output:将程序(内存)数据输出到磁盘、光盘等存储设备中
流的分类
按操作数据单位不同分为:字节流(一般用于传输二进制文件),字符流(一般用于传输文本文件)
按数据流的流向不同分为:输入流,输出流
按流的角色的不同分为:节点流,处理流/包装流
抽象基类 字节流 字符流
输入流 InputStream
Reader
输出流 OutputStream
Writer
节点流和处理流
节点流是底层流/低级流,直接与数据源相关(例如:FileInputStream 专用于操作文件,ByteArrayInputStream 专用于操作数组,等等)
处理流又称包装流,既可以消除不同节点流之间的实现差异,也可以提供更加方便的方法来完成输入和输出。底层对节点流进行了包装,试了修饰器设计模式,不会与数据源直接相连
性能的提高:主要以增加缓冲的方式来提高输入输出的效率。
操作的便捷:处理流可能提供了一系列便捷的方法来一次输入输出大批量的数据,使用更加灵活方便
节点输入输出流 文件字节节点流
基本介绍 :
FileInputStream 类是 InputStream 类的子类
FileInputStream 类每次只读取一个字节
构造方法 :
1 2 3 public FileInputStream (String filePath) { }
常用方法 :
public int read():从指定文件中读取一个字节,再次调用会从上次读取完的位置继续一个字节,该文件内容读取完毕会返回-1
public int read(byte[] b):从指定文件中读取指定字节数组大小的字节(每次读取一个字节,然后放入该字节数组中),返回读取字节的个数,读取完毕返回-1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 package com.itcz;import java.io.FileInputStream;import java.io.IOException;public class FileInputStreamTest { public static void main (String[] args) { FileInputStream fileInputStream = null ; try { fileInputStream = new FileInputStream ("E:\\demo.txt" ); int data = 0 ; while ((data = fileInputStream.read()) != -1 ) { System.out.print((char ) data); } } catch (IOException e) { throw new RuntimeException (e); } finally { try { fileInputStream.close(); } catch (IOException e) { throw new RuntimeException (e); } } System.out.println(); byte [] bytes = new byte [8 ]; try { fileInputStream = new FileInputStream ("E:\\demo.txt" ); int dataLen = 0 ; while ((dataLen = fileInputStream.read(bytes)) != -1 ) { System.out.print(new String (bytes, 0 , dataLen)); } } catch (IOException e) { throw new RuntimeException (e); } finally { try { fileInputStream.close(); } catch (IOException e) { throw new RuntimeException (e); } } } }
FileOutputStream
基本介绍 :
FileOutputStream 类是 OutputStream 类的子类
FileOutputStream 类每次只写入一个字节
如果文件不存在,会创建该文件
构造方法 :
1 2 3 4 5 6 7 public FileOutStream (String filePath) { } public FileOutStream (String filePath, boolean append) { }
常用方法 :
public void write(int byte):写入单个字节
public void write(byte[] b):通过字节数组,写入多个字节
public void write(byte[] b, int off, int len):通过指定范围(从 off 开始,写入len 个字节)的字节数组,写入多个字节
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 import java.io.FileOutputStream;import java.io.IOException;public class FileOutputStreamTest { public static void main (String[] args) { FileOutputStream fileOutputStream = null ; try { fileOutputStream = new FileOutputStream ("E:\\demo1.txt" , true ); String str = "hello, world" ; byte [] bytes = str.getBytes(); fileOutputStream.write(bytes, 0 , 3 ); } catch (IOException e) { throw new RuntimeException (e); } finally { try { fileOutputStream.close(); } catch (IOException e) { throw new RuntimeException (e); } } } }
文件字符节点流 FileReader
基本介绍 :
FileReader 类是 OutputStreamReader 类的子类,而 OutputStreamReader 类又是 Reader 类的子类
FileReader 类对象每次只读取一个字符,使用字符数组的方法进行读取,也是每次只读取一个字符,但是每次都从字符数组中读取字符
构造方法 :
1 2 3 public FileReader (File file) {}public FileReader (String FilePaint
常用方法 :
public int write(int c):读取单个字符,文件读取完毕返回-1
public int write(char[] chars):读取指定字符数组大小个字符,每次将读取的字符存入字符数组中,返回读取到的字符个数,文件读取完毕返回-1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 import java.io.FileReader;import java.io.IOException;public class FileReaderTest { public static void main (String[] args) { FileReader fileReader = null ; try { fileReader = new FileReader ("E:\\story.txt" ); int data = 0 ; while ((data = fileReader.read()) != -1 ) { System.out.print((char ) data); } } catch (IOException e) { throw new RuntimeException (e); } finally { try { fileReader.close(); } catch (IOException e) { throw new RuntimeException (e); } } System.out.println(); try { fileReader = new FileReader ("E:\\story.txt" ); int dataLen = 0 ; char [] chars = new char [8 ]; while ((dataLen = fileReader.read(chars)) != -1 ) { System.out.print(new String (chars, 0 , dataLen)); } } catch (IOException e) { throw new RuntimeException (e); } finally { try { fileReader.close(); } catch (IOException e) { throw new RuntimeException (e); } } } }
FileWriter
基本介绍 :
FileWriter 类是 OutputStreamWriter 类的子类,而 OutputStreamWriter 类又是 Writer 类的子类
FileWriter 类对象每次只写入一个字符,使用字符数组的方法进行写入,也是每次只写入一个字符,但是每次都从字符数组中读取字符,然后写入文件
如果文件不存在,会创建该文件
构造方法 :
1 2 3 4 5 public FileWriter (File file) {}public FileWriter (String FilePath) {}public FileWriter (File file / String filePath, boolean append) {}
常用方法 :
public void write(int c):写入单个字符
public void write(char[] chars):写入指定字符数组
public void write(char[] chars, int off, int len):写入指定范围的字符数组,从off 开始,写入 len 个字符
public void write(String str):写入整个字符串
public void write(String str, int off, int len):写入字符串的指定部分,从off 开始,写入 len 个字符
FileWriter 类的对象使用完毕后,一定要调用 flush() 或 close() 方法,不然内容无法写入文件
包装输入输出流 字符处理流 BufferedReader
基本介绍 :
该处理流对 Reader 类下的所有字符输入流进行了封装,通过构造器接收某个字符输入流,即可对对应的数据源进行处理
该类继承了 Reader 类
构造方法 :
1 2 3 public BufferedReader (Reader reader) { this .reader = reader; }
常用方法 :
public String readLine():每次读取指定文件一行的内容,每次读取从下次读取位置继续读取,文件读取完毕后返回null
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import java.io.BufferedReader;import java.io.FileReader;import java.io.IOException;public class BufferedReaderTest { public static void main (String[] args) { String filePath = "E:\\story.txt" ; BufferedReader bufferedReader = null ; try { bufferedReader = new BufferedReader (new FileReader (filePath)); String dataLine = null ; while ((dataLine = bufferedReader.readLine()) != null ) { System.out.println(dataLine); } } catch (IOException e) { throw new RuntimeException (e); } finally { try { bufferedReader.close(); } catch (IOException e) { throw new RuntimeException (e); } } } }
BufferedWriter
基本介绍 :
该处理流对 Writer 类下的所有字符输出流进行了封装,通过构造器接收某个字符输出流,即可对对应的数据源进行处理
该类继承了 Writer 类
构造方法 :
1 2 3 public BufferedWriter (Writer writer) { this .writer = writer; }
常用方法 :
public void write(String str):往对应的数据源写入字符串
public void newLine():往对应的数据源插入一个和操作系统相关的换行符
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import java.io.BufferedWriter;import java.io.FileWriter;import java.io.IOException;public class BufferedWriterTest { public static void main (String[] args) { BufferedWriter bufferedWriter = null ; String filePath = "E:\\demo.txt" ; try { bufferedWriter = new BufferedWriter (new FileWriter (filePath, true )); bufferedWriter.write("hello, world" ); bufferedWriter.newLine(); bufferedWriter.write("你好,世界" ); } catch (IOException e) { throw new RuntimeException (e); } finally { try { bufferedWriter.close(); } catch (IOException e) { throw new RuntimeException (e); } } } }
字节处理流
基本介绍 :
该类继承了 FilterInputStream 类,而 FilterInputStream 类继承了 InputStream 类
该处理流对 InputStream 类下的所有字节输入流进行了封装,通过构造器接收某个字节输入流,即可对对应的数据源进行处理
构造方法 :
1 2 3 public BufferedInputStream (InputStream inputStream) { this .in = inputStream; }
常用方法 :
public int read():从指定文件中读取一个字节,再次调用会从上次读取完的位置继续一个字节,该文件内容读取完毕会返回-1
public int read(byte[] b):从指定文件中读取指定字节数组大小的字节(每次读取一个字节,然后放入该字节数组中),返回读取字节的个数,读取完毕返回-1
BufferedOutputStream
基本介绍 :
该类继承了 FilterOutputStream 类,而 FilterOutputStream 类继承了 OutputStream 类
该处理流对 OutputStream 类下的所有字节输出流进行了封装,通过构造器接收某个字节输出流,即可对对应的数据源进行处理
构造方法 :
1 2 3 public BufferedOutputStream (OutputStream outputStream) { this .out = outputStream; }
常用方法 :
public void write(int byte):写入单个字节
public void write(byte[] b):通过字节数组,写入多个字节
public void write(byte[] b, int off, int len):通过指定范围(从 off 开始,写入len 个字节)的字节数组,写入多个字节
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 package com.itcz;import java.io.*;public class BufferStreamTest { public static void main (String[] args) { BufferedInputStream bis = null ; BufferedOutputStream bos = null ; String inputPath = "E:\\logo.png" ; String outputPath = "E:\\logo1.png" ; try { bis = new BufferedInputStream (new FileInputStream (inputPath)); bos = new BufferedOutputStream (new FileOutputStream (outputPath)); byte [] b = new byte [1024 ]; int dataLen = 0 ; while ((dataLen = bis.read(b)) != -1 ) { bos.write(b, 0 , dataLen); } } catch (IOException e) { throw new RuntimeException (e); } finally { try { bis.close(); bos.close(); } catch (IOException e) { throw new RuntimeException (e); } } } }
对象处理流
基本介绍 :
该类实现了 ObjectOutput 接口和 OjbectStreamConstants 接口
该处理流负责将文件中的对象的信息和类型读取到内存中(反序列化)
构造方法 :
1 2 3 public ObjectInputStream (InputStrem in) { this .in = in; }
常用方法 :
public Integer readInt(Integer num):反序列化Integer类的对象
public Boolean readBoolean(Boolean flag):反序列化Bollean类的对象
public Character readChar(Character c):反序列化Character类的对象
public Double readDouble(Double d):反序列化Double类的对象
public String readUTF(String str):反序列化字符串类型的对象
public Object readObject(Object obj):反序列化一个实现了 Serializable 接口或者 Externalizable 接口的类的对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import java.io.FileInputStream;import java.io.IOException;import java.io.ObjectInputStream;public class ObjectInputStreamTest { public static void main (String[] args) { try (ObjectInputStream objectInputStream = new ObjectInputStream (new FileInputStream ("E:\\demo.dat" ))) { System.out.println(objectInputStream.readInt()); System.out.println(objectInputStream.readBoolean()); System.out.println(objectInputStream.readChar()); System.out.println(objectInputStream.readUTF()); System.out.println(objectInputStream.readDouble()); Object dog = objectInputStream.readObject(); System.out.println(dog); if (dog instanceof Dog) { System.out.println(((Dog) dog).getName()); System.out.println(((Dog) dog).getAge()); } } catch (IOException | ClassNotFoundException e) { throw new RuntimeException (e); } } }
ObjectOutputStream
基本介绍 :
该类实现了 ObjectInput 接口和 OjbectStreamConstants 接口
该处理流负责将对象的信息和类型从内存中写入文件中(序列化)
构造方法 :
1 2 3 public ObjectOutputStream (OutputStrem out) { this .out = out; }
常用方法 :
public void writeInt(Integer num):序列化Integer类的对象
public void writeBoolean(Boolean flag):序列化Bollean类的对象
public void writeChar(Character c):序列化Character类的对象
public void writeDouble(Double d):序列化Double类的对象
public void writeUTF(String str):序列化字符串类型的对象
public void writeObject(Object obj):序列化一个实现了 Serializable 接口或者 Externalizable 接口的类的对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import java.io.FileOutputStream;import java.io.IOException;import java.io.ObjectOutputStream;import java.io.Serializable;public class ObjectOutputStreamTest { public static void main (String[] args) { ObjectOutputStream objectOutputStream = null ; try { objectOutputStream = new ObjectOutputStream (new FileOutputStream ("E:\\demo.dat" )); objectOutputStream.write(100 ); objectOutputStream.writeBoolean(true ); objectOutputStream.writeChar('A' ); objectOutputStream.writeUTF("你好,世界" ); objectOutputStream.writeDouble(1.1 ); objectOutputStream.writeObject(new Dog ("小花" , 3 )); } catch (IOException e) { throw new RuntimeException (e); } finally { try { objectOutputStream.close(); } catch (IOException e) { throw new RuntimeException (e); } } } }
细节 :
对某个文件进行序列化或反序列化时,代码中读写顺序要一致
序列化或反序列化的对象对应的类必须实现 Serializable 接口或者 Externalizable 接口
序列化的类中建议添加SerialVersionUID属性,为了提高版本的兼容性
1 private static final long serialVersionUID = 1L ;
即当该类中添加属性时,序列化或反序列化该对象时不会认为该类变成了一个全新的类,而是把它当作之前类的升级版
序列化对象时,默认将里面所有属性都进行序列化,但除了static或transient修饰的成员
序列化对象时,要求里面属性的类型也需要实现序列化接口
序列化具备可继承性,也就是如果某类已经实现了序列化,则它的所有子类也已经默认实现了序列化
转换处理流 基本介绍 :
InputStreamReader:Reader 的子类,可以将 InputStream(字节流) 转换成Reader(字符流)
OutputStreamWriter:Writer的子类,可以将 OutputStream(字节流) 转换成Writer(字符流)
当处理纯文本数据时,如果使用字符流效率更高,并且可以有效解决中文问题,所以建议将字节流转换成字符流
可以在使用时指定编码格式(比如utf-8,gbk,gb2312,ISO8859-1等)
构造方法 :
1 2 3 public InputStreamReader (InputStream inputStream, Charset charset) { }
将字节流转换为字符流,并且可以指定转换格式,这样就不会存在中文乱码问题,未指定时默认为UTF-8编码格式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import java.io.BufferedReader;import java.io.FileInputStream;import java.io.IOException;import java.io.InputStreamReader;public class InputStreamReaderTest { public static void main (String[] args) { BufferedReader bufferedReader = null ; try { InputStreamReader isr = new InputStreamReader (new FileInputStream ("E:\\demo.txt" ), "gbk" ); bufferedReader = new BufferedReader (isr); String data = null ; while ((data = bufferedReader.readLine()) != null ) { System.out.println(data); } } catch (IOException e) { throw new RuntimeException (e); } finally { try { bufferedReader.close(); } catch (IOException e) { throw new RuntimeException (e); } } } }
OutputStreamWriter 构造方法 :
1 2 3 public OutputStreamReader (OutputStream outputStream, Charset charset) { }
将字节流转换为字符流,并且可以指定转换格式,这样就不会存在中文乱码问题,未指定时默认为UTF-8编码格式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 package com.itcz;import java.io.BufferedWriter;import java.io.FileOutputStream;import java.io.IOException;import java.io.OutputStreamWriter;public class OutputStreamWriterTest { public static void main (String[] args) throws IOException { BufferedWriter bufferedWriter = new BufferedWriter (new OutputStreamWriter (new FileOutputStream ("E:\\demo1.txt" ), "gbk" )); bufferedWriter.write("你好,世界" ); bufferedWriter.close(); } }
打印处理流 基本介绍 :
打印流只有输出流,没有输入流
打印流负责将数据输出到显示器或者文件中
PrintStream
基本介绍 :
该处理流是字节打印处理流,System 工具类中的 out 属性就是 PrintStream 类型
该处理流是 FilterOutStream 类的子类, FilterOutStream 类是 OutputStream 类的子类
常用方法 :
public void print(String str):打印字符串到指定位置
public void write(String str):打印字符串到指定位置
可以通过System.setOut(PrintStream printStream)方法,重定向输出设备
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import java.io.IOException;import java.io.PrintStream;public class PrintStreamTest { public static void main (String[] args) throws IOException { PrintStream printStream = System.out; printStream.print("你好,世界" ); printStream.write("你好,世界" .getBytes()); System.setOut(new PrintStream ("E:\\demo.txt" )); System.out.print("hello,world" ); printStream.close(); } }
PrintWriter
基本介绍 :该打印流是字符打印处理流,该处理流是 Writer 类的子类常用方法 :
public void print(String str):打印字符串到指定位置
public void write(String str):打印字符串到指定位置
构造方法 :
1 2 3 public PrintWriter (OutputStream out) { }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import java.io.FileWriter;import java.io.IOException;import java.io.PrintWriter;public class PrintWriterTest { public static void main (String[] args) throws IOException { PrintWriter printWriter = new PrintWriter (new FileWriter ("E:\\demo.txt" ,true )); printWriter.print("你好,世界" ); printWriter.write("hello, world" ); printWriter.close(); } }
网络编程 InetAddress
基本介绍 :该类主要用于获取主机或者服务器的域名和IP地址常用方法 :
getLocalHost():获取本地主机的主机名和IP地址
getByName(String str):根据指定主机名/域名获取IP地址对象
getHostName():获取InetAddress对象的主机名
getHostAddress():获取InetAddress对象的IP地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import java.net.InetAddress;import java.net.UnknownHostException;public class InetAddressTest { public static void main (String[] args) throws UnknownHostException { InetAddress inetAddress = InetAddress.getLocalHost(); System.out.println(inetAddress); InetAddress inetAddress1 = InetAddress.getByName("www.baidu.com" ); System.out.println(inetAddress1); InetAddress inetAddress2 = InetAddress.getByName("ASUS" ); String hostName = inetAddress2.getHostName(); System.out.println(hostName); String hostAddress = inetAddress2.getHostAddress(); System.out.println(hostAddress); } }
Socket
基本介绍 :
在Java中服务端和客户端都通过Socket类来发送请求和接收请求,不同是的服务端还需要通过ServerSocket类来监听端口
该类专用于建立TCP连接传递数据
构造方法 :
1 2 3 public Socket (String hostAddress, int port) { }
常用方法 :
getInputStream():该方法可以获取到InputStream类的对象,通过该对象可以获取到客户端发送的数据
getOutputStream():该方法可以获取到OutputStream类的对象,通过该对象可以向服务端发送的数据
shutdownOutput():该方法用于提示对方自己的数据发送完毕,防止死锁的发生,也可以通过writer.newLine()方法写入结束标记,但是读取必须使用reader.readLine()方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 import java.io.*;import java.net.ServerSocket;import java.net.Socket;public class SocketServerTest { public static void main (String[] args) throws IOException { System.out.println("服务端启动,监听9999端口" ); ServerSocket serverSocket = new ServerSocket (9999 ); Socket socket = serverSocket.accept(); InputStream inputStream = socket.getInputStream(); BufferedReader bufferedReader = new BufferedReader (new InputStreamReader (inputStream)); String data = null ; if ((data = bufferedReader.readLine()) != null ) { System.out.println(data); } OutputStream outputStream = socket.getOutputStream(); BufferedWriter bufferedWriter = new BufferedWriter (new OutputStreamWriter (outputStream)); bufferedWriter.write("hello, client" ); bufferedWriter.newLine(); bufferedWriter.flush(); bufferedWriter.close(); bufferedReader.close(); socket.close(); serverSocket.close(); System.out.println("服务器退出了" ); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 import java.io.*;import java.net.InetAddress;import java.net.Socket;import java.net.UnknownHostException;public class SocketClientTest { public static void main (String[] args) throws IOException { System.out.println("客户端启动" ); Socket socket = new Socket (InetAddress.getLocalHost(), 9999 ); OutputStream outputStream = socket.getOutputStream(); OutputStreamWriter outputStreamWriter = new OutputStreamWriter (outputStream); BufferedWriter bufferedWriter = new BufferedWriter (outputStreamWriter); bufferedWriter.write("hello, server" ); bufferedWriter.newLine(); bufferedWriter.flush(); InputStream inputStream = socket.getInputStream(); InputStreamReader inputStreamReader = new InputStreamReader (inputStream); BufferedReader bufferedReader = new BufferedReader (inputStreamReader); String data = null ; while ((data = bufferedReader.readLine()) != null ) { System.out.println(data); } System.out.println("客户端退出" ); bufferedWriter.close(); bufferedReader.close(); socket.close(); } }
ServerSocket
基本介绍 :该类用于服务端监听端口常用方法 :public Socket accept():当客户端与服务端监听的端口建立TCP连接后,会返回一个Socket对象,否则服务端会一直堵塞在该方法中
DatagramSocket 和 DatagramPacket 基本介绍 :
类 DatagramSocket 和 DatagramPacket(数据报)实现了基于 UDP 协议网络程序
UDP数据报通过数据报套接字 DatagramSocket 发送和接收,系统不保证 UDP 数据报一定能够安全送到目的地,也不能确定什么时候抵达
DatagramPacket 类的对象封装了 UDP 数据报,在数据报中包含了发送端的IP地址和端口号以及接收端的IP地址和端口号
UDP 协议中每个数据报都给出了完整的地址信息,因此发送数据报前无需建立连接
UDP 协议中传输的数据报大小最大为64k
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import java.io.IOException;import java.net.*;public class UDPSender { public static void main (String[] args) throws IOException { System.out.println("启动客户端" ); DatagramSocket socket = new DatagramSocket (8888 ); byte [] bytes = "hello, 今天晚上吃火锅" .getBytes(); DatagramPacket packet = new DatagramPacket (bytes, bytes.length, InetAddress.getLocalHost(), 9999 ); socket.send(packet); byte [] bytes1 = new byte [1024 ]; DatagramPacket packet1 = new DatagramPacket (bytes1, bytes1.length); socket.receive(packet1); int length = packet1.getLength(); byte [] data = packet1.getData(); System.out.println(new String (data, 0 , length)); socket.close(); System.out.println("客户端退出" ); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 import java.io.IOException;import java.net.DatagramPacket;import java.net.DatagramSocket;import java.net.InetAddress;import java.net.SocketException;public class UDPReceiver { public static void main (String[] args) throws IOException { System.out.println("启动服务端" ); DatagramSocket socket = new DatagramSocket (9999 ); byte [] bytes = new byte [1024 ]; DatagramPacket packet = new DatagramPacket (bytes, bytes.length); socket.receive(packet); int length = packet.getLength(); byte [] data = packet.getData(); System.out.println(new String (data, 0 , length)); byte [] bytes1 = "好的" .getBytes(); DatagramPacket packet1 = new DatagramPacket (bytes1, bytes1.length, InetAddress.getLocalHost(), 8888 ); socket.send(packet1); socket.close(); System.out.println("服务端退出" ); } }
反射 反射机制
基本概念 :
反射机制允许程序在执行期借助于ReflectionAPI取得任何类的内部信息(比如成员变量,构造器,成员方法等等),并能操作对象的属性及方法。反射在设计模式和框架底层都会用到
加载完类之后,在堆中就产生了一个Class类型的对象(一个类只有一个Class对象),这个对象包含了类的完整结构信息。通过这个对象得到类的结构。这个对象就像一面镜子,透过这个镜子看到类的结构,所以,形象的称之为:反射
反射相关的主要类 :
java.lang.Class:类对象,Class对象标识某个类加载后在堆中的对象
java.lang.reflect.Method:代表类的方法,Method对象表示某个类的方法
java.lang.reflect.Field:代表类的成员变量,Field对象表示某个类的成员变量
java.lang.reflect.Constructor:代表类的构造方法,Constructor对象表示构造器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 import java.lang.reflect.Constructor;import java.lang.reflect.Field;import java.lang.reflect.InvocationTargetException;import java.lang.reflect.Method;@SuppressWarnings({"all"}) public class Reflect01 { public static void main (String[] args) throws Exception { Class cls = Class.forName("com.itcz.Cat" ); Object o = cls.newInstance(); System.out.println("o的运行类型为" + o.getClass()); Method methodName = cls.getMethod("cry" ); methodName.invoke(o); Field fieldName = cls.getField("age" ); System.out.println(fieldName.get(o)); Constructor constructor = cls.getConstructor(); System.out.println(constructor); Constructor constructor1 = cls.getConstructor(String.class); System.out.println(constructor1); } } class Cat { private String name; public int age; public Cat (String name) { this .name = name; } public Cat () {} public void cry () { System.out.println(name + "喵喵喵叫......." ); } }
Class 类
基本介绍 :
Class也是类,因此也继承了Object类
Class类对象不是new出来的,而是系统创建的
对于某个类的Class类对象,在内存中只有一份,因为类只加载一次
每个类的实例都会记得自己是由哪个Class实例所生成
通过Class可以完整地得到一个类的完整结构,通过一系列API
Class对象是存在在堆中
类的字节码二进制数据,是放在方法区的,有的地方称为类的元数据
常用方法 :
方法名 功能说明
static Class forName(String name)
返回指定类名 name的Class对象
Object newInstance()
调用缺省构造函数,返回该Class对象的一个实例
getName()
返回此Class对象所表示的实体(类、接口、数组类、基本类型等)名称
Class [] getInterfaces()
获取当前Class对象的接口
ClassLoader getClassLoader()
返回该类的类加载器
Class getSuperclass()
返回表示此Class所表示的实体的超类的Class
Constructor[] getConstructors()
返回一个包含某些Constructor对象的数组
Field[] getDeclaredFields()
返回Field对象的一个数组
Method getMethod(String name,Class … paramTypes)
返回一个Method对象,此对象的形参类型为paramType
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 import java.lang.reflect.Field;public class Reflect02 { public static void main (String[] args) throws ClassNotFoundException, IllegalAccessException, NoSuchFieldException, InstantiationException { String classFullName = "com.itcz.Car" ; Class<?> cls = Class.forName(classFullName); System.out.println(cls); System.out.println(Class.class); System.out.println(cls.getPackage().getName()); System.out.println(cls.getName()); Object obj = cls.newInstance(); Field brand = cls.getField("brand" ); brand.set(obj, "宝马" ); System.out.println(brand.get(obj)); Field[] fields = cls.getFields(); for (Field field : fields) { System.out.println(field.getName()); } } } class Car { public String brand; public int price; public Car () { } public Car (String brand, int price) { this .brand = brand; this .price = price; } public String getBrand () { return brand; } public void setBrand (String brand) { this .brand = brand; } public int getPrice () { return price; } public void setPrice (int price) { this .price = price; } }
可以通过以下几种方式获取Class类对象 :
已知一个类的全类名,且该类在类路径下,可以通过Class类的静态方法forName()获取,可能抛出ClassNotFoundException异常,应用场景:多用于配置文件,读取类的全路径,加载类
已知具体的类,可以通过类名.class获取,应用场景:多用于参数传递,比如通过反射得到对应构造器对象
已知某个类的实例,通过调用该实例的getClass()方法获取Class对象,应用场景:通过创建好的对象,获取Class对象
通过类加载器获取到类对象
对于基本数据类型,使用 基本数据类型名.class 获取Class类对象
对于基本数据类型的包装类,使用 包装类名.TYPE 获取Class类对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public class Reflect03 { public static void main (String[] args) throws ClassNotFoundException { Class<?> cls1 = Class.forName("java.lang.String" ); System.out.println(cls1); Class<String> cls2 = String.class; System.out.println(cls2); Car car = new Car (); Class<? extends Car > cls3 = car.getClass(); System.out.println(cls3); ClassLoader classLoader = car.getClass().getClassLoader(); Class<?> cls4 = classLoader.loadClass("java.lang.String" ); System.out.println(cls4); Class<Integer> integerClass = int .class; Class<Character> characterClass = char .class; System.out.println(integerClass); Class<Integer> type1 = Integer.TYPE; Class<Character> type2 = Character.TYPE; System.out.println(type2); } }
类加载
分类 :
静态加载:编译时加载相关的类,如果没有则报错,依赖性太强
动态加载:运行时加载需要的类,如果运行时不用该类,则不报错,降低了依赖性
加载时机 :
当通过new关键字创建对象时,加载该类的信息,该加载属于静态加载
当子类被加载时,父类也加载,该加载属于静态加载
调用类中的静态成员时,该加载属于静态加载
通过反射创建对象时,该加载属于动态加载
加载分为三个阶段 :
加载阶段:JVM在该阶段的主要目的是将字节码从不同的数据源(可能是class文件、也可能是jar包,甚至网络)转化为二进制字节流加载到内存中,并生成一个代表该类的java.lang.Class对象
链接 阶段:
验证:目的是为了确保Class文件的字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身的安全。包括:文件格式验证(是否以魔数oxcafebabe开头)、元数据验证、字节码验证和符号引用验证,可以考虑使用-Xverify:none参数来关闭大部分的类验证措施,缩短虚拟机类加载的时间。
准备:JVM会在该阶段对静态变量分配内存并默认初始化(对应数据类型的默认初始值,如0、OL、null、false等)。这些变量所使用的内存都将在方法区中进行分配
解析:虚拟机将常量池内的符号引用替换为直接引用的过程
初始化:到初始化阶段,才真正开始执行类中定义的Java程序代码,此阶段是执行()方法的过程。()方法是由编译器按语句在源文件中出现的顺序,依次自动收集类中的所有静态变量的赋值动作和静态代码块中的语句,并进行合并。虚拟机会保证一个类的()方法在多线程环境中被正确地加锁、同步,如果多个线程同时去初始化一个类,那么只会有一个线程去执行这个类的()方法,其他线程都需要阻塞等待,直到活动线程执行()方法完毕
Java程序执行的流程 :
编译阶段:将java文件编译成class文件
类加载阶段:将java文件中的类信息和静态属性加载到内容
执行阶段:依次执行java文件中定义的语句
通过反射获取类的所有结构信息
java.lang.Class类中的方法 :
getName:获取全类名
getSimpleName:获取简单类名
getFields:获取所有public修饰的属性,包含本类以及父类的
getDeclaredFields:获取本类中所有属性
getMethods:获取所有public修饰的方法,包含本类以及父类的
getDeclaredMethods:获取本类中所有方法
getConstructors:获取所有public修饰的本类的构造器
getDeclaredConstructors:获取本类中所有构造器
getPackage:以Package形式返回 包信息
getSuperClass:以Class形式返回父类信息
getlnterfaces:以Class[]形式返回接口信息
getAnnotations:以Annotation[]形式返回注解信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 import java.lang.annotation.Annotation;import java.lang.reflect.Constructor;import java.lang.reflect.Field;import java.lang.reflect.Method;public class Reflect04 { public static void main (String[] args) throws ClassNotFoundException { Class<?> person = Class.forName("com.itcz.Person" ); System.out.println(person.getName()); System.out.println(person.getSimpleName()); Field[] fields = person.getFields(); for (Field field : fields) { System.out.println("本类以及父类的public修饰的属性=" + field.getName()); } Field[] declaredFields = person.getDeclaredFields(); for (Field declaredField : declaredFields) { System.out.println("本类的属性=" + declaredField.getName()); } Method[] methods = person.getMethods(); for (Method method : methods) { System.out.println("本类以及父类的public修饰的方法=" + method.getName()); } Method[] declaredMethods = person.getDeclaredMethods(); for (Method declaredMethod : declaredMethods) { System.out.println("本类的方法=" + declaredMethod.getName()); } Constructor<?>[] constructors = person.getConstructors(); for (Constructor<?> constructor : constructors) { System.out.println("本类以及父类的public修饰的构造器=" + constructor.getName()); } Constructor<?>[] declaredConstructors = person.getDeclaredConstructors(); for (Constructor<?> declaredConstructor : declaredConstructors) { System.out.println("本类的构造方法=" + declaredConstructor.getName()); } System.out.println(person.getPackage()); System.out.println(person.getSuperclass()); Class<?>[] interfaces = person.getInterfaces(); for (Class<?> anInterface : interfaces) { System.out.println(anInterface.getName()); } Annotation[] annotations = person.getAnnotations(); for (Annotation annotation : annotations) { System.out.println(annotation); } } } interface IA {} interface IB {} @Deprecated class Person implements IA , IB { public String name; protected int age; String job; private double salary; public Person () { } public Person (String name, int age, String job, double salary) { this .name = name; this .age = age; this .job = job; this .salary = salary; } public String getName () { return name; } public void setName (String name) { this .name = name; } public int getAge () { return age; } public void setAge (int age) { this .age = age; } public String getJob () { return job; } public void setJob (String job) { this .job = job; } public double getSalary () { return salary; } public void setSalary (double salary) { this .salary = salary; } }
java.lang.reflect.Field类中的方法 :
getModifiers:以int形式返回修饰符 [说明:默认修饰符是0,public是1,private是2,protected是4,static 是8,final是16],public(1)+static(8)=9
getType:以Class形式返回类型
getName:返回属性名
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import java.lang.reflect.Field;public class Reflect05 { public static void main (String[] args) throws ClassNotFoundException { Class<?> aClass = Class.forName("com.itcz.Dog" ); Field[] fields = aClass.getDeclaredFields(); for (Field field : fields) { System.out.println("本类的属性名为" + field.getName() + " 该属性名的修饰符为" + field.getModifiers() + " 该属性对应的数据类型为" + field.getType()); } } } class Dog { private String name; public int age; String hobby; }
java.lang.reflect.Method类中的方法 :
getModifiers:以int形式返回修饰符[说明:默认修饰符是0,public 是1,private是2,protected是4,static是8,final是16]
getReturnType:以Class形式获取 返回类型
getName:返回方法名
getParameterTypes:以Class[]返回参数类型数组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import java.lang.reflect.Method;public class Reflect06 { public static void main (String[] args) throws ClassNotFoundException { Class<?> fish = Class.forName("com.itcz.Fish" ); Method[] declaredMethods = fish.getDeclaredMethods(); for (Method declaredMethod : declaredMethods) { System.out.println("Fish类的方法名=" + declaredMethod.getName() + " 该方法的修饰符=" + declaredMethod.getModifiers() + " 该方法的返回值类型=" + declaredMethod.getReturnType()); Class<?>[] parameterTypes = declaredMethod.getParameterTypes(); for (Class<?> parameterType : parameterTypes) { System.out.println("该方法的形参=" + parameterType); } } } } class Fish { public void m1 (String name, int age, String hobby) { } protected void m2 () { } void m3 () { } private void m4 () { } }
java.lang.reflect.Constructor类中的方法 :
getModifiers:以int形式返回修饰符
getName:返回构造器名(全类名)
getParameterTypes:以Class[]返回参数类型数组
通过反射创建对象
方式一 :调用类中的public修饰的无参构造器方式二 :调用类中的public修饰的指定构造器方式三 :调用类中的private修饰的指定构造器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 import java.lang.reflect.Constructor;public class Reflection01 { public static void main (String[] args) throws Exception { Class<?> userClass = Class.forName("com.itcz.reflection.User" ); Object o = userClass.newInstance(); System.out.println(o); Constructor<?> constructor = userClass.getConstructor(String.class, int .class); Object o1 = constructor.newInstance("李四" , 20 ); System.out.println(o1); Constructor<?> declaredConstructor = userClass.getDeclaredConstructor(String.class); declaredConstructor.setAccessible(true ); Object o2 = declaredConstructor.newInstance("王五" ); System.out.println(o2); } } class User { private String name = "张三" ; private int age = 18 ; public User () { } public User (String name, int age) { this .name = name; this .age = age; } private User (String name) { this .name = name; } @Override public String toString () { return "User{" + "name='" + name + '\'' + ", age=" + age + '}' ; } }
Class类相关的方法 :
newInstance:调用类中的无参构造器,获取对应类的对象
getConstructor(Class…clazz):根据参数列表,获取对应的public修饰的构造器对象
getDeclaredConstructor(Class…clazz):根据参数列表,获取对应的构造器对象
Constructor类相关的方式 :
setAccessible:爆破,这样就可以通过私有构造器创建对象
newInstance(Object…obj):调用构造器
通过反射操作属性
方式一:操作public修饰的属性
方式二:操作非public修饰的属性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import java.lang.reflect.Field;public class Reflection02 { public static void main (String[] args) throws Exception { Class<?> studentClass = Class.forName("com.itcz.reflection.Student" ); Object o = studentClass.newInstance(); Field ageField = studentClass.getField("age" ); ageField.set(o, 20 ); System.out.println(ageField.get(o)); Field nameField = studentClass.getDeclaredField("name" ); nameField.setAccessible(true ); nameField.set(null , "李四" ); System.out.println(nameField.get(null )); } } class Student { public int age = 18 ; private static String name = "张三" ; public Student () { } public Student (int age, String name) { this .age = age; this .name = name; } }
Class类相关的方法:
getDeclaredField(String fieldName):根据属性名获取属性对象
getField(String fieldName):根据属性名获取public修饰的属性对象
Field类相关的方法:
setAccessible(boolean flag):爆破,此时就可以操作private修饰的属性
set(Object obj, Ojbect value):给该属性赋值
get(Object obj):获取该属性的值
如果是静态属性,则get和set方法中的obj参数,可以写成null
通过反射操作方法
方式一:操作public修饰的方法
方式二:操作非public修饰的方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import java.lang.reflect.Method;public class Reflection03 { public static void main (String[] args) throws Exception { Class<?> managerClass = Class.forName("com.itcz.reflection.Manager" ); Object o = managerClass.newInstance(); Method m1 = managerClass.getMethod("m1" , String.class); m1.invoke(o, "张三" ); Method m2 = managerClass.getDeclaredMethod("m2" , String.class, int .class, char .class); m2.setAccessible(true ); System.out.println(m2.invoke(null , "李四" , 18 , '男' )); Object returnValue = m2.invoke(null , "李四" , 18 , '男' ); System.out.println(returnValue.getClass()); } } class Manager { private String name; public void m1 (String name) { System.out.println(name); } private static String m2 (String name, int age, char gender) { return name + age + gender; } }
Class类相关的方法:
getDeclaredMethod(String methodName, Class…clazz):根据方法名和形参列表获取方法对象
getMethod(String methodName, Class…clazz):根据方法名和形参列表获取public修饰的方法对象
Method类相关的方法:
setAccessible(boolean flag):爆破,此时就可以操作private修饰的方法
invoke(Ojbect obj, Object…vale):调用该方法
如果是静态方法,则invoke方法中的obj参数,可以写成null
正则表达式 匹配的底层原理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 import java.util.regex.Matcher;import java.util.regex.Pattern;public class RegTheory { public static void main (String[] args) { String content = "中共中央、国务院14日上午在人民大会堂举行2026年春节团拜会。中共中央总书记、国家主席、中央军委主席习近平发表讲话,代表党中央和国务院,向全国各族人民,向香港特别行政区同胞、澳门特别行政区同胞、台湾同胞和海外侨胞拜年。" + "习近平强调,即将过去的乙巳蛇年,是很不平凡的一年。面对复杂多变的国际国内形势,我们迎难而上、砥砺前行,推动党和国家事业取得新进展新成效,全年经济社会发展主要目标任务顺利完成,“十四五”圆满收官,我国经济实力、科技实力、国防实力、综合国力跃上新台阶,中国式现代化迈出新的坚实步伐。" + " 李强主持团拜会,赵乐际、王沪宁、蔡奇、丁薛祥、李希、韩正等出席。" + " 人民大会堂宴会厅灯光璀璨、喜气洋洋,各界人士2000多人欢聚一堂、共迎佳节,现场洋溢着欢乐祥和的节日气氛。" ; String regStr = "(\\d\\d)(\\d\\d)" ; Pattern pattern = Pattern.compile(regStr); Matcher matcher = pattern.matcher(content); while (matcher.find()) { System.out.println("找到:" + matcher.group(0 )); System.out.println("第一组:" + matcher.group(1 )); System.out.println("第二组:" + matcher.group(2 )); } } }
正则表达式语法 贪婪匹配和非贪婪匹配 默认是贪婪匹配,例如字符串为”oooo”,正则表达式为”o+”,则匹配的结果为oooo
可以通过?紧随任何其他限定符(*、+、?、{n}、{n,}、{n,m})之后时,将匹配模式改为非贪婪匹配,此时匹配结果为4个o
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import java.util.regex.Matcher;import java.util.regex.Pattern;public class RegStr03 { public static void main (String[] args) { String content = "oooo" ; String regStr = "o+?" ; Pattern pattern = Pattern.compile(regStr); Matcher matcher = pattern.matcher(content); while (matcher.find()) { System.out.println(matcher.group(0 )); } } }
转义字符 在使用正则表达式去检索某些特殊字符时,需要使用转义字符,否则检索不到结果,甚至会报错,故而会使用转义字符\。例如:*+()$/?[]^{}这些字符都会使用转义字符来表达它们原来的意思
限定符 用于指定其前面的字符和组合项连续出现多少次
符号 含义 示例 说明
*
指定字符重复0次或n次(无要求)零到多
(abc)*
仅包含任意个abc的字符串,等效于\w*
+
指定字符重复1次或n次(至少一次)1到多
m+(abc)*
以至少1个m开头,后接任意个abc的字符串
?
指定字符重复0次或1次(最多一次)0到1
m+abc?
以至少1个m开头,后接ab或abc的字符串
{n}
只能输入n个字符
[abcd]{3}
由abcd中字母组成的任意长度为3的字符串
{n,}
指定至少n个匹配
[abcd]{3,}
由abcd中字母组成的任意长度不小于3的字符串
{n,m}
指定至少n个但不多于m个匹配
[abcd]{3,5}
由abcd中字母组成的任意长度不小于3,不大于5的字符串
字符匹配符
符号 含义 示例 解释
[]
可接收的字符列表
[efgh]
e、f、g、h中的任意一个字符
[^]
不接收的字符列表
[^abc]
除a、b、c之外的任意一个字符,包括数字和特殊符号
-
连字符
A-Z
任意单个大写字母
.
匹配除 \n 以外的任何字符
a..b
以a开头,b结尾,中间包括2个任意字符的长度为4的字符串
\d
匹配单个数字字符,相当于[0-9]
\d{3}(\d)?
包含3个或4个数字的字符串
\D
匹配单个非数字字符,相当于[^0-9]
\D(\d)*
以单个非数字字符开头,后接任意个数字字符串
\w
匹配单个数字、大小写字母字符,相当于[0-9a-zA-Z]
\d{3}\w{4}
以3个数字字符开头的长度为7的数字字母字符串
\W
匹配单个非数字、大小写字母字符,相当于[^0-9a-zA-Z]
\W+\d{2}
以至少1个非数字字母字符开头,2个数字字符结尾的字符串
\s
匹配任何空白字符(空格,制表符等)
-
-
\S
匹配任何非空白字符,和\s刚好相反
-
-
Java正则表达式默认是区分字母大小写,可以通过以下方式不区分大小写:
(?i)abc 表示abc都不区分大小写
a(?i)bc 表示bc都不区分大小写
a((?i)b)c 表示b不区分大小写
Pattern pattern = Pattern.compile(regStr, Pattern.CASE_INSENSITIVE)
分组组合和反向引用符 捕获分组
捕获分组构造形式 说明
(pattern)
非命名捕获。捕获匹配的子字符串。编号为零的第一个捕获是由整个正则表达式模式匹配的文本,其他捕获结果则根据左括号的顺序从1开始自动编号
(?pattern)
命名捕获。将匹配的子字符串捕获到一个组名称或编号名称中。用于name的字符串不能包含任何标点符号,并且不能以数字开头,可以使用单引号代替尖括号,例如(?’name’)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import java.util.regex.Matcher;import java.util.regex.Pattern;public class RegStr01 { public static void main (String[] args) { String content = "helloworld1192,nihaoshijie2290" ; String regStr = "(?<g1>\\d\\d)(?<g2>\\d\\d)" ; Pattern pattern = Pattern.compile(regStr); Matcher matcher = pattern.matcher(content); while (matcher.find()) { System.out.println("匹配到的文本为:" + matcher.group(0 )); System.out.println("匹配到的文本的第一个分组为:" + matcher.group(1 )); System.out.println("匹配到的文本的第一个分组为(通过命名捕获):" + matcher.group("g1" )); System.out.println("匹配到的文本的第二个分组为:" + matcher.group(2 )); System.out.println("匹配到的文本的第二个分组为(通过命名捕获):" + matcher.group("g2" )); } } }
非捕获分组
非捕获分组构造形式 说明
( ?: pattern)
匹配pattern但不捕获该匹配的子表达式,即它是一个非捕获匹配,不存储供以后使用的匹配。这对于用”or”字符(
( ?= pattern)
它是一个非捕获匹配。例如,‘Windows( ?= 95
( ?! pattern)
该表达式匹配不处于匹配pattern的字符串的起始点的搜索字符串。它是一个非捕获匹配。例如,‘Windows( ?! 95
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import java.util.regex.Matcher;import java.util.regex.Pattern;public class RegStr02 { public static void main (String[] args) { String content = "张三老师,张三同学,张三教育" ; String regStr = "张三(?!老师|同学)" ; Pattern pattern = Pattern.compile(regStr); Matcher matcher = pattern.matcher(content); while (matcher.find()) { System.out.println("找到:" + matcher.group(0 )); } } }
反向引用 圆括号的内容被捕获后,可以在这个括号后被使用,从而写出一个比较实用的匹配模式,这个称之为反向引用,这种引用既可以是在正则表达式的内部,也可以是在正则表达式的外部,内部反向引用使用 \分组号 $分组号
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import java.util.regex.Pattern;public class RegStr07 { public static void main (String[] args) { String content = "我....我要....学学....学学习习习Java" ; Pattern pattern = Pattern.compile("\\." ); content = pattern.matcher(content).replaceAll("" ); content = Pattern.compile("(.)\\1+" ).matcher(content).replaceAll("$1" ); System.out.println("content=" + content); } }
选择匹配符 在匹配某个字符串的时候是选择性的,即:既可以匹配这个,又可以匹配那个,这是就可以使用选择匹配符
定位符 定位符,规定要匹配的字符串出现的位置,比如在字符串的开始还是结束位置
符号 含义 示例 说明
^
指定起始字符
^[0-9]+[a-z]*
以至少一个数字开头,后接任意个小写字母的字符串
$
指定结束字符
^[0-9]\-[a-z]+$
以一个数字开头后接连字符-,并以至少一个小写字母结尾的字符串
\b
匹配目标字符串的边界
han\b
查找边界为han的子字符串,边界可以是字符串的结束位置,也可以是子串间有空格
\B
匹配目标字符串的非边界
han\B
和\b含义相反
Pattern 基本概念 :pattern 对象是一个正则表达式对象。Pattern类没有公共构造方法。要创建一个Pattern对象,调用其公共静态方法,它返回一个Pattern对象。该方法接受一个正则表达式作为它的第一个参数,比如:Pattern r=Pattern.compile(pattern);
常用方法 :public static boolean matches(pattern, content),该方法用于整体匹配字符串
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import java.util.regex.Matcher;import java.util.regex.Pattern;public class RegStr04 { public static void main (String[] args) { String content = "10https://www.bilibili.com/video/BV1fh411y7R8?spm_id_from=333.788.player.switch&vd_source=4ad0a2f2ad6c40766c4bfa7c008aaa3f&p=895" ; String regStr = "((http|https)://)?([\\w-]+\\.)+[\\w-]+(\\/[\\w-/._?=&%#]*)?" ; boolean isMatch = Pattern.matches(regStr, content); if (isMatch) { System.out.println("整体匹配成功" ); } else { System.out.println("整体匹配失败" ); } Pattern pattern = Pattern.compile(regStr); Matcher matcher = pattern.matcher(content); if (matcher.find()) { System.out.println("匹配成功" ); } else { System.out.println("匹配失败" ); } } }
Matcher 基本概念 :Matcher 对象是对输入字符串进行解释和匹配的引擎。与Pattern类一样,Matcher也没有公共构造方法。需要调用Pattern对象的matcher 方法来获得一个 Matcher对象
常用方法 :
方法名 说明
public int start()
返回以前匹配的初始索引
pulblic int end()
返回最后匹配字符之后的偏移量
public boolean find()
尝试查找与该模式匹配的输入序列的下一个子序列
public boolean matches()
尝试将整个区域与模式匹配
public String replaceAll(String replacement)
替换模式与给定替换模式串相匹配的输入序列的每一个子序列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import java.util.regex.Matcher;import java.util.regex.Pattern;public class RegStr05 { public static void main (String[] args) { String content = "123 aoshudingli hello nihao hello 123" ; String regStr1 = "hello" ; String regStr2 = "hello.*" ; String regStr3 = "123" ; Pattern pattern1 = Pattern.compile(regStr1); Matcher matcher1 = pattern1.matcher(content); while (matcher1.find()) { System.out.println(matcher1.start()); System.out.println(matcher1.end()); System.out.println("找到:" + content.substring(matcher1.start(), matcher1.end())); } Pattern pattern2 = Pattern.compile(regStr2); Matcher matcher2 = pattern2.matcher(content); if (matcher2.matches()) { System.out.println("整体匹配成功" ); } else { System.out.println("整体匹配失败" ); } Pattern pattern3 = Pattern.compile(regStr3); Matcher matcher3 = pattern3.matcher(content); String newContent = matcher3.replaceAll("234" ); System.out.println("替换后的字符串为" + newContent); } }

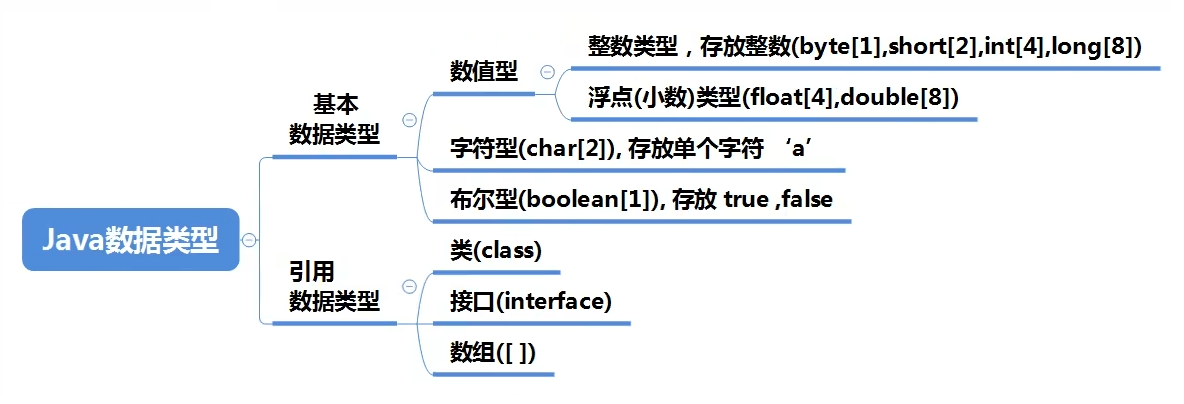
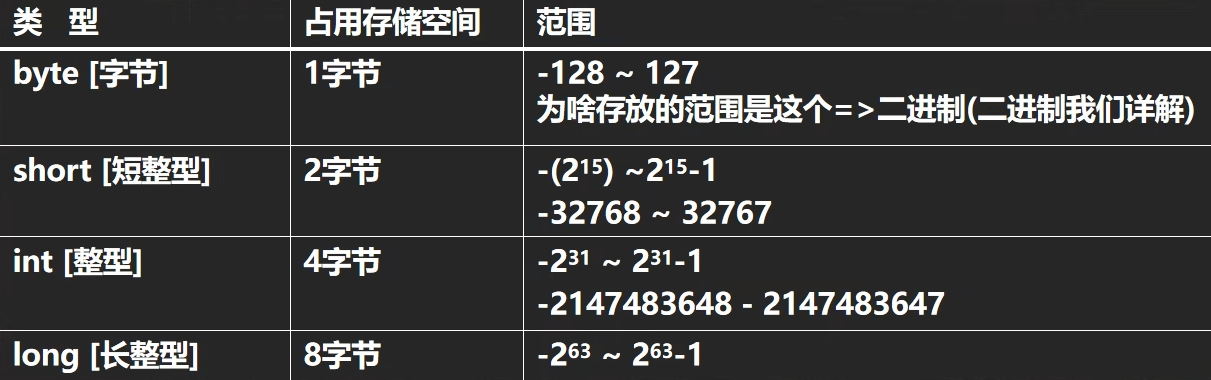


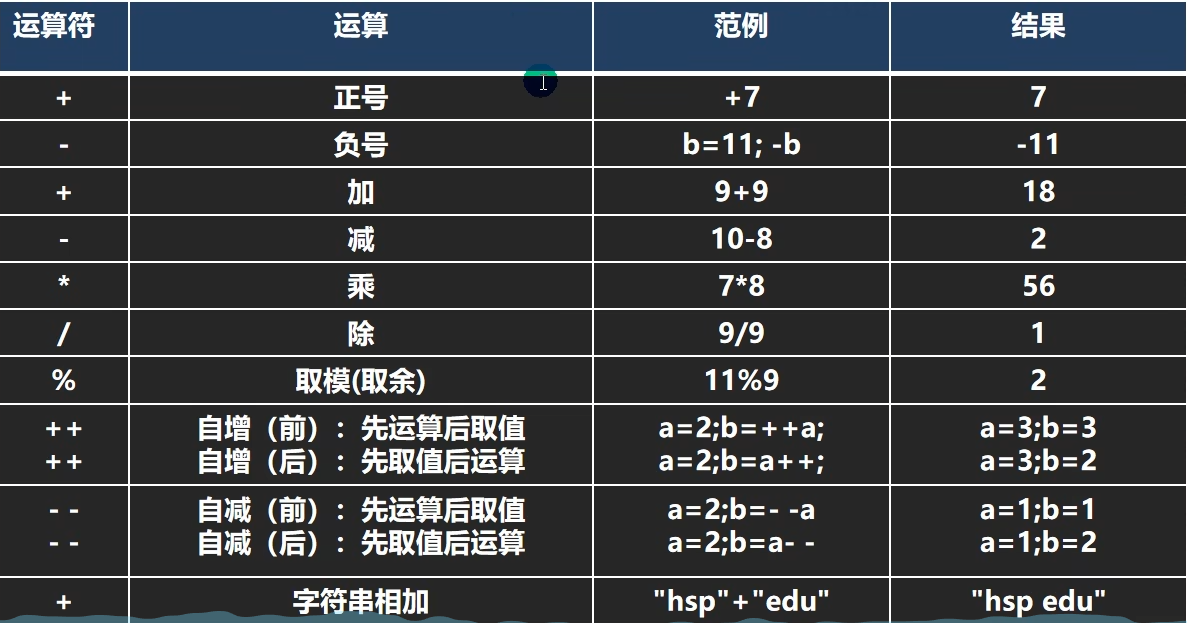
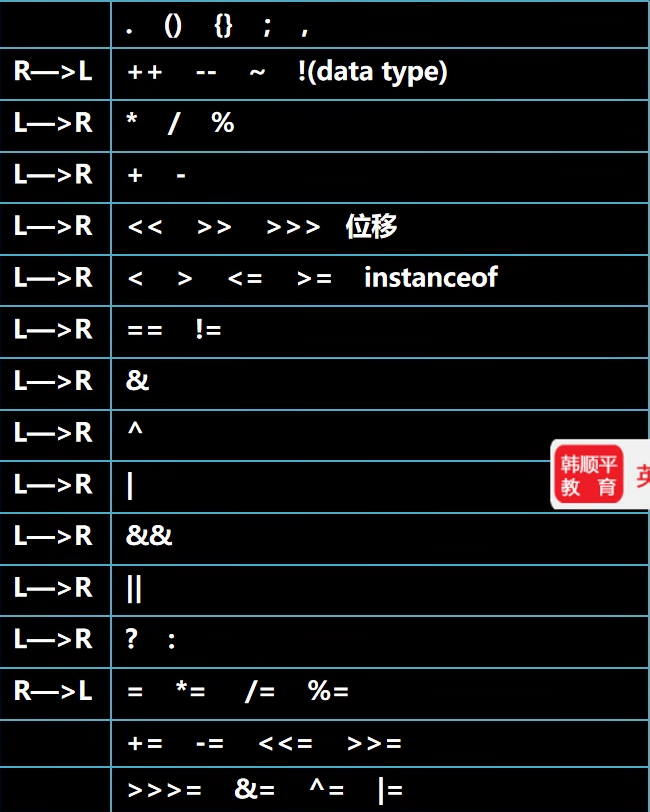
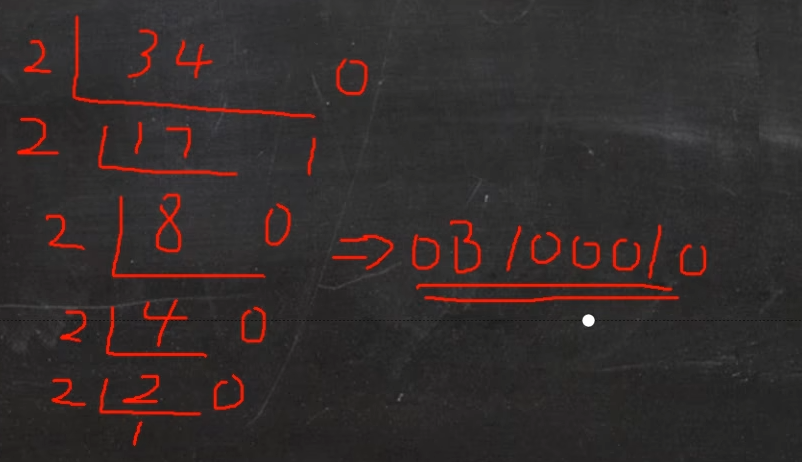
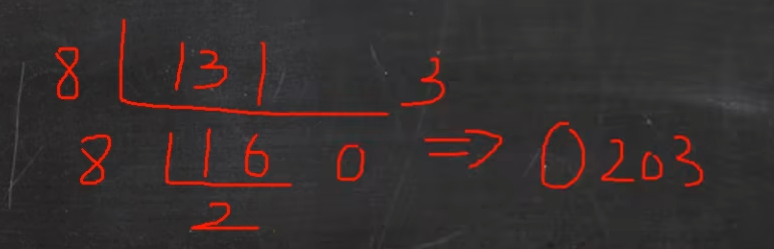
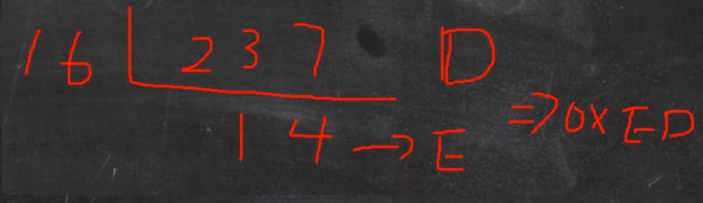
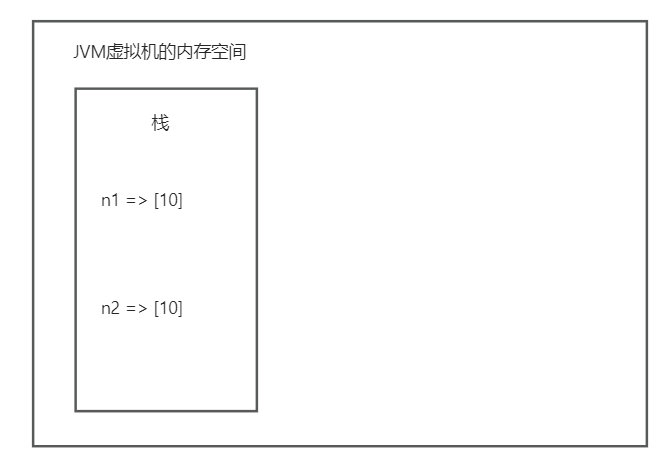
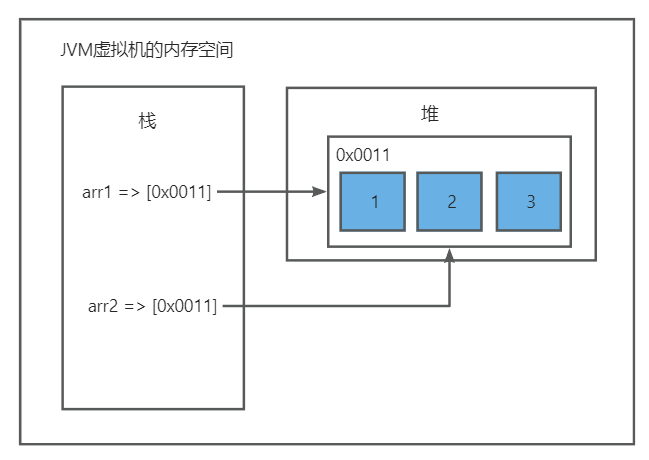
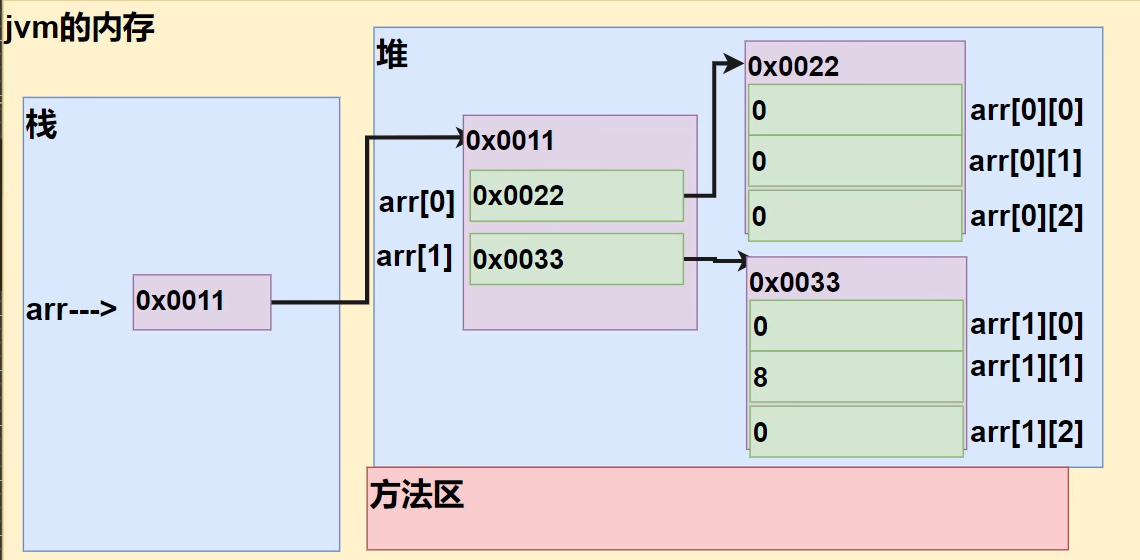
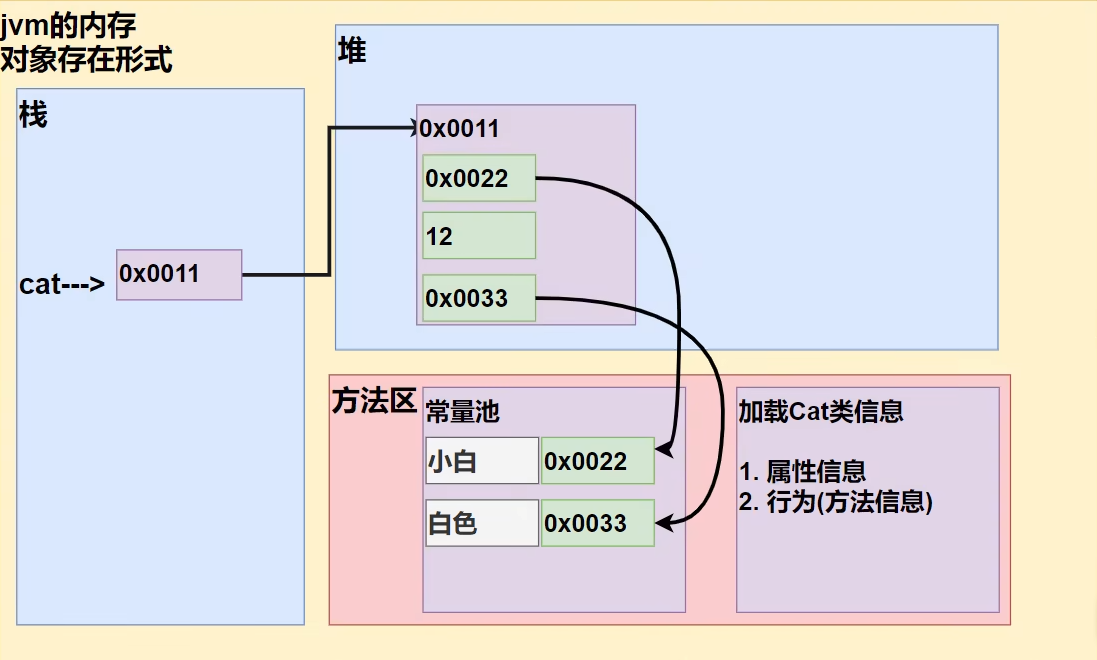
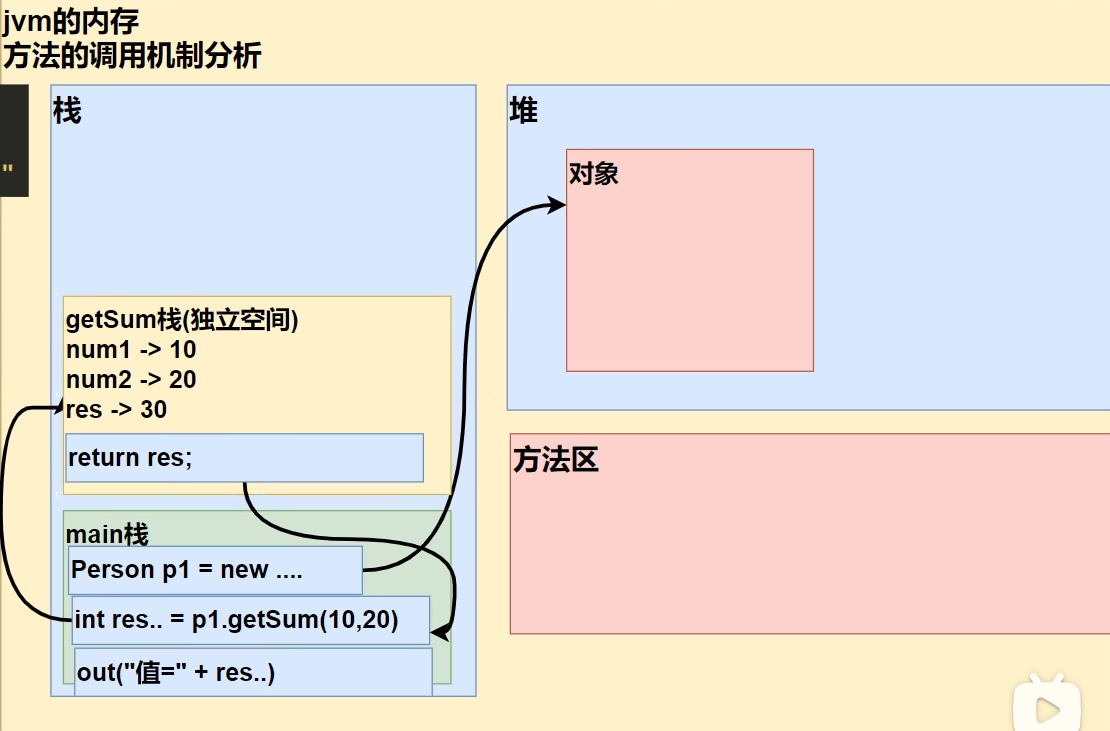
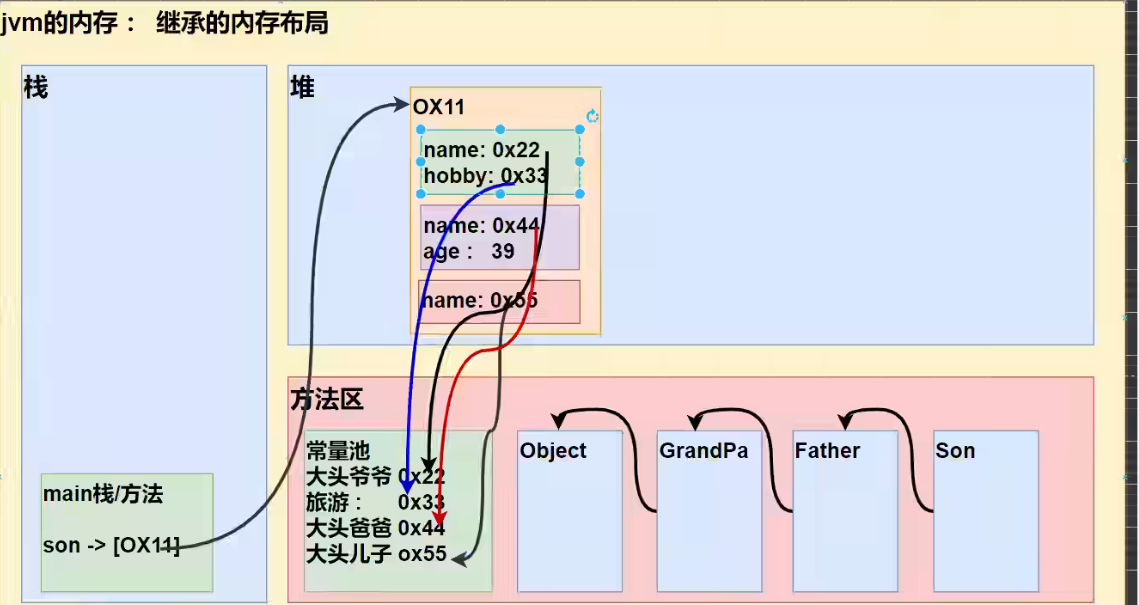
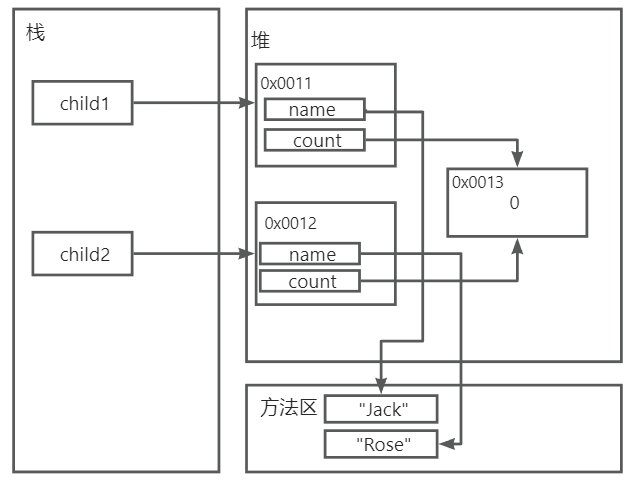
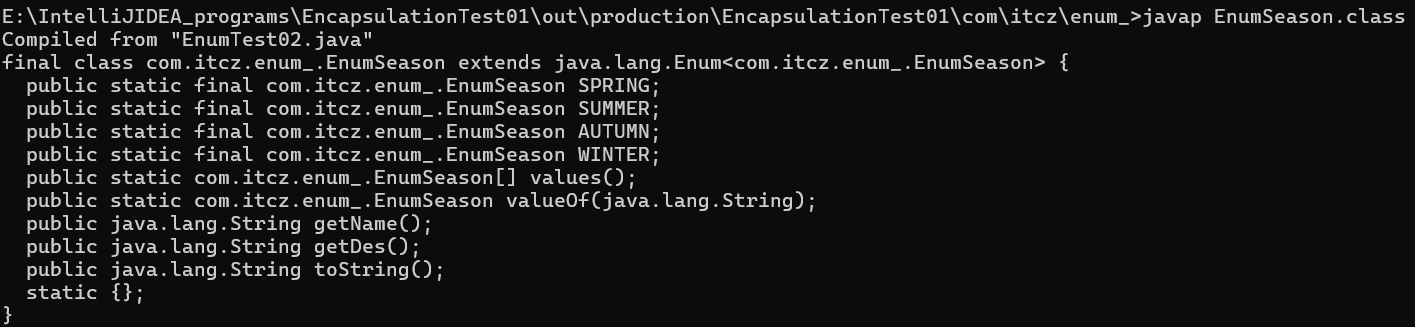 + 传统的定义对象常量的语法简化成了对象常量名(形参列表)
+ 如果使用无参构造器创建枚举对象,可以将小括号省略
+ 当有多个枚举对象时,使用逗号间隔,最后一个用分号结尾
+ 枚举对象必须放在枚举类的行首
+ 该枚举类的构造器默认是私有的,故而可以省略private修饰符
+ 因为enum 关键字开发枚举类时,默认会继承Enum类,故而该枚举类不能再继承其他类(单继承),但是可以实现接口
3. **Enum类的常用方法**:因为enum修饰的枚举类默认会继承Enum类,故而可以调用Enum类的方法
+ toString:Enum类已经重写了toString方法了,返回的是当前枚举对象的对象名,子类可重写该方法
+ name:返回当前对象名,子类中不能重写
+ ordinal:返回当前对象的位置号,默认从0开始
+ vlaues:返回当前枚举类中的所有对象常量
+ valueOf:将字符串转换为枚举对象,要求字符串必须为已有的常量名,否则报异常
+ compareTo:比较两个枚举对象,比较的是编号
+ 传统的定义对象常量的语法简化成了对象常量名(形参列表)
+ 如果使用无参构造器创建枚举对象,可以将小括号省略
+ 当有多个枚举对象时,使用逗号间隔,最后一个用分号结尾
+ 枚举对象必须放在枚举类的行首
+ 该枚举类的构造器默认是私有的,故而可以省略private修饰符
+ 因为enum 关键字开发枚举类时,默认会继承Enum类,故而该枚举类不能再继承其他类(单继承),但是可以实现接口
3. **Enum类的常用方法**:因为enum修饰的枚举类默认会继承Enum类,故而可以调用Enum类的方法
+ toString:Enum类已经重写了toString方法了,返回的是当前枚举对象的对象名,子类可重写该方法
+ name:返回当前对象名,子类中不能重写
+ ordinal:返回当前对象的位置号,默认从0开始
+ vlaues:返回当前枚举类中的所有对象常量
+ valueOf:将字符串转换为枚举对象,要求字符串必须为已有的常量名,否则报异常
+ compareTo:比较两个枚举对象,比较的是编号